
Статья опубликована в рамках: XXXI Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 28 апреля 2015 г.)
Наука: Математика
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

ИСПОЛЬЗОВАНИЕ БИНАРНЫХ ДЕРЕВЬЕВ В МЕТОДЕ КОДИРОВАНИЯ ХАФФМАНА
Димитренко Егор Владимирович
студент 3 курса факультета информатики СГАУ им. Академика Королева, РФ, г. Самара
E -mail: Egoka93@yandex.ru
Швецов Александр Юрьевич
студент 3 курса факультета информатики, СГАУ им. Академика Королева, РФ, г. Самара
E -mail: shvetsovalex007@gmail.com
Тишин Владимир Викторович
научный руководитель, доцент, кафедра прикладной математики СГАУ им. академика С.П. Королева, РФ, г. Самара
Как правило, множество типов данных характеризуется избыточностью. Для человеческого восприятия, избыточность прямым образом влияет на качество понимания какой-либо информации. Если же перейти к цифровому представлению информации, а именно как она представлена в ЭВМ, то роль избыточности является отрицательной, так как при ее передаче, хранении и обработке увеличиваются затраты для всех этих процессов. Рассматривая обработку больших объемов информации и принимая в расчет существующие в данный момент устройства хранения с ограниченным пространством памяти, а также учитывая лавинное увеличение информации в обществе, проблема избыточности и непосредственно сжатия информации имеет явную актуальность на сегодняшний день [3].
Существует два основных метода сжатия информации:
· Необратимый метод сжатия — при сжатии информации происходит потеря какой-то части исходных данных. Тем самым меняется содержимое и при обратной операции (разархивации) мы получаем исходную информацию в неполном объеме. Как правило, встречается в формате: JPEG, MP3
· Обратимый метод сжатия — меняется лишь структура данных, а содержимое остается без изменений. При обратной операции восстанавливаются все исходные данные. Данный метод характеризуется меньшим уровнем сжатия в отличие от необратимого. Данным метод используется при архивации форматами ZIP,ARJ,RAR.
В основе большинства алгоритмов сжатия информации лежит метод кодирования Хаффмана. Для генерации такого кода необходимо построение кодового дерева.
Выделим основные цели нашей работы:
1. Исследование применения деревьев при кодировании методом Хаффмана
2. Программная реализация кодирования методом Хаффмана
3. Визуализация кодового дерева для демонстрации работы алгоритма. Сравнение коэффициентов сжатия русскоязычного и англоязычного текстов.
Рассматриваемый нами метод разработан в 1952 году Дэвидом Хаффманом. Американским исследователем в области теории информации. Алгоритм относится к обратимым методам сжатия и является оптимальным. Как правило, кодирование Хаффмана состоит из двух этапов:
1. Построение дерева с оптимальными кодами для каждого символа алфавита, на основе частоты встречаемости во входной последовательности
2. Построение словаря вида: код — символ для дальнейшего декодирования.
Особенности алгоритма:
· Гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву.
· Алгоритм является двухпроходным
Одна из основных идей алгоритма: чем выше степень присутствия символа в данном тексте, тем меньше код этого символа.

Рисунок 1. Пример работы алгоритма
Разберем на примере (рис. 1). После частотного анализа текста, состоящего из букв А, В, С и D, мы получили вероятности этих символов и добавили их в список в качестве узлов дерева. Выбрали два узла с наименьшим весом. Новый узел сформировали с весом, равным сумме весов выбранных узлов, и добавили к нему два выбранных в качестве дочерних. В списке заменили два предыдущих узла на вновь сформированный. Повторяли слияние вершин дерева до тех пор, пока в списке не остался один узел — корень. Так мы построили все вершины дерева и обозначили необходимые связи между ними. В нашей программной реализации каждый узел представляет собой объект класса, который хранит информацию о своем весе и дочерних узлах, причем вершина с наименьшим весом будет помечаться нулем, а с большим — единицей. После этого программа вычисляет код по построенному бинарному дереву для каждого его листа — символа исходного текста [1, c. 45]. Для лучшего понимания механизма построения кода, наша программа визуализирует построенное дерево (рис. 2). Построение кода идет от корня к листу. Полученные коды символов: А — 0, В — 10, С — 111, D — 110. Так как ни один код не является префиксом для другого, то гарантируется однозначность данного типа кодирования [3].
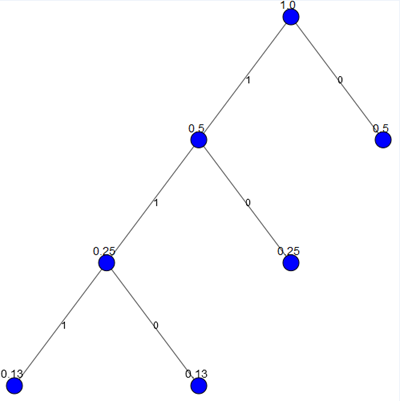
Рисунок 2. Кодовое дерево Хаффмана для алфавита ABCD
Также с помощью написанной программы мы сравнили эффективность сжатия русскоязычного и англоязычного текстов. Коэффициент сжатия k определяется как отношение объема исходных данных к объему сжатых данных. Благодаря ему можно сравнивать характеристики различных алгоритмов сжатия на одном тексте или сравнивать эффективность сжатия различных текстов, используя один алгоритм сжатия. Следует отметить:
· Если k = 1, алгоритм не осуществляет сжатия, и входной текст оказывается равен объему выходного
· Если k < 1, алгоритм не осуществляет сжатия, а наоборот порождает выходной текст большего размера, таким образом, совершает паразитную работу
Мы выбрали несколько русскоязычных и англоязычных текстов примерно одинаковой длины и вычислили для них коэффициенты сжатия (рис. 3). И вот какие результаты мы получили:
· для русскоязычного текста — 1,994
· для англоязычного — 2,259

Рисунок 3. Кодовое дерево Хаффмана на основе англоязычного текста и на основе русского
Таким образом, нами была реализована программа для кодирования данных методом Хаффмана и визуализации бинарного дерева, используемого в алгоритме. Были проанализированы коэффициенты сжатия русскоязычных и англоязычных текстов. В результате этого анализа мы получили, что текст на английском языке сжимается с большей эффективностью.
Список литературы:
1.Зыков А.А. Основы теории графов. М: Вузовская книга, 2004. — 664 с.
2.ИТМО, конспект лекций [Электронный ресурс] — Режим доступа. — URL: http://neerc.ifmo.ru/wiki/index.php?title=Алгоритм_Хафммана (дата обращения 20.04.2015).
3.Фурсов В.А. Теория информации: Самара: Изд-во Самара, СГАУ, 2011. — 45 с.
дипломов