
Статья опубликована в рамках: XXVIII Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 29 января 2015 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

РАЗРАБОТКА ПРОГРАММНОГО ПРОДУКТА ДЛЯ ОПРЕДЕЛЕНИЯ СТЕПЕНИ БЛИЗОСТИ ОБРАЗОВАТЕЛЬНЫХ СТАНДАРТОВ
Коновалов Роман Викторович
студент гр. 720-2 каф. КИБЭВС, факультета безопасности, Томского государственного университета систем управления и радиоэлектроники, РФ, г. Томск
E -mail: konovalovrv1992@gmail.com
Терентьев Денис Сергеевич
студент гр. 720-2 каф. КИБЭВС, факультета безопасности, Томского государственного университета систем управления и радиоэлектроники, РФ, г. Томск
E -mail: nicklid@mail.ru
Кручинин Дмитрий Владимирович
научный руководитель, аспирант каф. КИБЭВС, ТУСУР, РФ, г. Томск
Проблема сравнения текстовой информации и выявление степени сходства является одной из наиболее важных и трудных задач анализа данных и поиска информации. Учитывать схожесть текстовых документов необходимо при разработке поисковых систем и повышения их качества за счет удаления избыточной дублирующей информации, при объединении информации в тематические группы или фильтрации необходимой информации. Также определение схожести текстовых документов используется при установлении авторства или выявлении факта плагиата.
В данной работе ставится цель: получение оценки степени близости федеральных государственных образовательных стандартов третьего поколения.
Для достижения этой цели были поставлены задачи:
· обзор и анализ основных способов оценки близости текстовых документов;
· выбор метода для сравнения текстов;
· сравнение федеральных государственных образовательных стандартов третьего поколения.
Данная работа является актуальной в таких областях как:
· поисковые системы;
· тематический анализ;
· обработка неструктурированной информации.
Структура федерального государственного образовательного стандарта высшего профессионального образования по направлению подготовки [1]:
1. Область применения.
2. Используемые сокращения.
3. Характеристики направления подготовки — в этом разделе определяется нормативный срок, общая трудоемкость освоения основных образовательных программ (в зачетных единицах) и соответствующая квалификация (степень).
4. Характеристика профессиональной деятельности специалистов — определяются область, объекты профессиональной деятельности, виды, профессиональные задачи в соответствии с видами профессиональной деятельности и профилем подготовки.
5. Требования к результатам освоения основных образовательных программ (ООП) — компетенции, которыми должен обладать выпускник: общекультурные, профессиональные (общепрофессиональные, эксплуатационная деятельность, экспериментально-исследовательская, организационно-управленческая деятельность и т. д.), по специализациям. Каждая компетенция описывается словом «способность». Каждой компетенции назначен шифр, который в дальнейшем используется в учебных планах и программах для ее обозначения.
6. Требования к структуре ООП — данный раздел определяет учебные циклы и разделы, необходимые для подготовки специалиста:
· гуманитарный, социальный и экономический циклы;
· естественнонаучный цикл;
· профессиональный цикл;
· физическая культура;
· учебная и производственная практики и/или научно-исследовательская работа;
· итоговая государственная аттестация.
В данном разделе приведена структура ООП. Структура ООП включает в себя учебные циклы и проектируемые результаты их освоения. Результаты изучения формулируются с помощью слов «знать», «уметь», «владеть». Для базовой части цикла результаты определены ФГОС ВПО, для вариативной части циклов результаты формулируются вузом в ООП. Для каждого учебного цикла приведен перечень дисциплин, которые должны быть освоены в рамках данного цикла, и коды формируемых компетенций в результате обучения.
7. Требования к условиям реализации ООП — требования к вузу, аудиториям, видам занятий и их соотношению, трудоемкости дисциплин, количеству часов и количеству зачетных единиц, требования к проводимым вузом видам практик, требования к кадровому составу преподавателей, требования к методическому обеспечению, программному обеспечению и аппаратным средствам.
8. Оценка качества освоения ООП — определяет формы и процедуры контроля знаний, требования к разработке оценочных средств для контроля качества изучения программы.
При сопоставлении двух стандартов будем рассматривать два раздела, в которые в основном раскрывают компетентностный подход: требования к результатам освоения ООП и требования к структуре ООП. В первом разделе необходимо выделить из текста и сравнить компетенции. Во втором рассматриваемом разделе необходимо сопоставить информацию, представленную в таблице «Структура ООП» [2]. В данной таблице для каждого учебного цикла необходимо выделить:
· результаты их освоения, обозначенные словами «знать», «уметь», «владеть»;
· список дисциплин;
· список формируемых компетенций.
Остальные разделы стандартов можно не рассматривать ввиду наименьшей их информативности при сопоставлении двух стандартов.
При переводе студента с одной специальности на другую или при поступлении на второе высшее образование иногда возможно перезачесть оценки по некоторым дисциплинам, уже изученным студентам. В этом случае следует сопоставить два документа:
· план учебного процесса по специальности, на которую поступает студент;
· академическую справку, предоставляемую студенту.
План учебного процесса также имеет определенную структуру. В данном документе приведены дисциплины, изучаемые в рамках данной специальности, которые сгруппированы по учебным циклам в соответствии с ФГОС ВПО, номера семестров, в которых сдаются экзамены, зачеты и выполняются курсовые работы, и количество часов, выделяемых на освоение дисциплин.
Академическая справка содержит информацию о студенте и результатах его обучения на момент выдачи справки. В справке приведен перечень дисциплин, по которым студент был аттестован за время обучения, общее количество часов, выделяемое на освоение дисциплины, и итоговая оценка.
Для того, чтобы перезачесть оценку по какой-либо изученной студентом дисциплине, необходимо чтобы количество часов для данной дисциплины в академической справке было равно или превышало количество часов, заявленное для данной дисциплине в плане учебного процесса. Таким образом, чтобы сопоставить эти документы, необходимо сопоставить перечни дисциплин и количество часов. Всю остальную информацию, содержащуюся в данных документах, можно не учитывать.
Поиск по документу-образцу [4].
Целью поиска является, обнаружение тематически близких документов. Самым простым подходом к решению задачи поиска документов по образцу является использование всех слов документа-образца в качестве запроса.
Общую схему поиска по документу образцу можно представить в следующем виде (рис. 1).
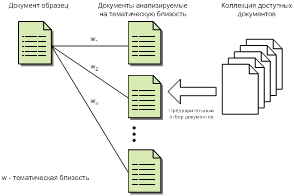
Рисунок 1. Поиск документов по образцу
Существует документ-образец и некоторая коллекция доступных документов. Выполняется предварительный отбор из коллекции документов, и затем для отобранных документов вычисляется тематическая близость. Вычисленные оценки тематической близости w1, …, wn используются при ранжировании документов по тематической близости к документу образцу.
Метод частотно-контекстной классификации тематики текста [5].
Предлагаемый подход к тематической классификации текстовой информации основывается на гипотезе о том, что словарный запас и частоты использования слов зависят от темы текста.
Тематическая классификация предполагает выделение множества ключевых слов, определяющих тематику текста. При этом каждому из них приписывается вес, определяющий значимость данного слова в тематике, т.е. какие-то ключевые слова играют большую роль в определении тематики, какие-то меньшую, но именно такая совокупность слов, с такой значимостью каждого из них в тематике и определяет тематическую направленность.
Такой подход обеспечивает снижение размерности за счет перехода от основного текста к его представлению в виде множества ключевых слов, приближенно описывающих его содержание. Это необходимо, прежде всего, для последующей тематической идентификации сравниваемых текстов.
Ключевые слова определяются по количеству их вхождений в текст, а именно — частота ключевых слов в тексте выше других слов.
Проблема заключается в определении порога (автоматизированном, машинном определении), который отделяет ключевые слова от всех остальных.
Очевидно, выбор пороговой величины должен зависеть от конкретного текста, от таких характеристик модели как d(M(I, R))max, d(M(I, R))min и n(I):
1) d(M(I, R))max — максимальная степень информационного элемента для информационной структуры M(I, R):
d(M(I, R))max = max d(i), ![]() ,
,
M(I, R) — информационная структура. Является совокупностью I — множества информационных элементов (вершин графа) и R — набора связей между этими элементами (ребер графа).
d(i) — степень информационного элемента:
d(i) = n(R(i)), ![]() ,
, ![]() ,
,
n(R(i)) — количество пар связей в наборе R(i).
2) d(M(I, R))min — минимальная степень информационного элемента для информационной структуры M(I, R):
d(M(I, R))min = min d(i), ![]() .
.
3) n(I) = | I | — количество информационных элементов множества I (количество уникальных слов в тексте).
Вспомогательные этапы обработки текста [3].
Удаление незначительных слов из рассматриваемых текстов в большинстве случаев является необходимым этапом предварительной обработки текста. Это значительно позволяет повысить эффективность алгоритма, сравнивающего или анализирующего документы. Используются два основных подхода.
Удаление по словарю. Необходимо предварительно составить словарь так называемых стоп-слов, которые не содержат значительную информацию.
Удаление слов по частоте. Слова, имеющие наибольшую частоту появления в тексте, чаще всего относятся к союзам, предлогам и другим незначащим словам, и являются шумом при анализе текста. Необходимо определить пороговую частоту появления слов, чтобы безошибочно удалять из анализируемого текста незначащие слова.
Так же значительно повысить эффективность любого из перечисленных методов можно с помощью предварительного морфологического и синтаксического анализа. В данном случае необходимо использовать соответствующие словари или прикладные программы.
Основное окно программы приведено на рисунке 2. На первой вкладке «Сравнить ФГОС» необходимо указать образовательные стандарты, которые необходимо сравнить. В «Результат» будет выведена таблица, в которой отображены оценки близости следующих частей стандарта: общекультурные компетенции (OK), профессиональные компетенции (PK), специализированные компетенции (PSK), гуманитарный цикл (C1), естественнонаучный (C2), профессиональный (C3) циклы.
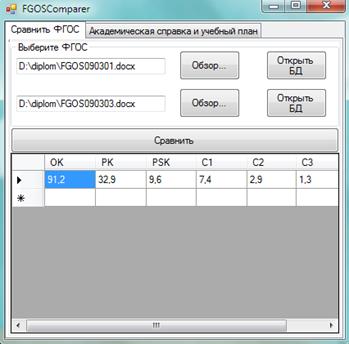
Рисунок 2. Вкладка «Сравнить ФГОС»
На второй вкладке «Академическая справка и учебный план» аналогично предлагается указать местоположение данных документов на компьютере, также план учебного процесса можно выбрать из базы данных. После нажатия на кнопку «Сравнить» будет выведена таблица, в которой будут указаны названия предметов, как они приведены в плане учебного процесса, так и в академической справке, и оценки, которые возможно перезачесть. Окно программы приведено на рисунке 3.

Рисунок 3. Вкладка «Академическая справка и учебный план»
Заключение
Проведено исследование основных методов анализа и оценки близости текстов. Был проведен анализ структуры и особенностей составления федеральных государственных образовательных стандартов третьего поколения. Для сравнения текстовых фрагментов стандартов был выбран метод частотно-контекстной классификации тематики текста, для которого будет реализовано приложение. Также были рассмотрены такие документы как план учебного процесса и академическая справка. Полученная программа будет предназначена для частичной автоматизации труда сотрудника при сопоставлении образовательных стандартов и принятии решения о переводе и зачислении студентов.
Список литературы:
1.Анализ текстовых документов для извлечения тематически сгруппированных ключевых терминов, [Электронный ресурс] –– Режим доступа. — URL: http://citforum.ru/database/articles/kw_extraction/ (дата обращения: 18.04.2014).
2.Министерство образования и науки, [Электронный ресурс] — Режим доступа. — URL: http://mon.gov.ru/
3.Модели и методы семантического сравнения строк символов в коллекции документов, [Электронный ресурс] –– Режим доступа. — URL: http://www.dissercat.com/content/modeli-i-metody-semanticheskogo-sravneniya-strok-simvolov-v-kollektsii-dokumentov (дата обращения: 10.05.2014).
4.Моченов С.В., Бледнов А.М., Луговских Ю.А. Применение статистических методов для семантического анализа Ижевск: НИЦ «Регулярная и хаотическая динамика», 2005.
5.Портал федеральных государственных образовательных стандартов, [Электронный ресурс] — Режим доступа. — URL: http://www.fgosvpo.ru/
дипломов