
Статья опубликована в рамках: XVI Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 21 января 2014 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

АНАЛИЗ РАБОТЫ SBC СОРТИРОВОК НА РЕАЛЬНЫХ СТАТИСТИЧЕСКИХ МОДЕЛЯХ
Орлов Андрей Геннадьевич
студент 3 курса, кафедра КС СНУЯЭиП, Украина г. Севастополь
E-mail: orel777@mail.ru
Моисеев Дмитрий Владимирович
научный руководитель, канд. техн. наук, доцент каф. КС, Украина г. Севастополь
Введение
В настоящее время множество программистов-теоретиков, а так же разработчиков ПО во всём мире занимаются проблемой оптимизации работы с данными. Одна из таких проблем — это сортировка данных. За последние пол века бурного развития компьютерных наук наш мир претерпел значительные изменения, между тем многие проблемы сортировок так не решены. На данный момент программисты работая с сортировками данных пользуются О-нотацией, которая показывает лучшее и худшее теоретическое время работы алгоритма, но не показывает зависимость между временем сортировки и размером входных данных. В данной статье будет рассмотрена группа обменных сортировок SBC в которую войдут: глупая сортировка (англ. stupid sort), пузырьковая сортировка (англ. bubble sort), шейкерная сортировка (англ. cocktail sort). Группу SBC так же будем называть группой пузырькового типа, по той причине, что все 3 алгоритма построены по одному принципу – принципу «всплывающего» значения (пузырька).
Цель данной статьи: проанализировать работу SBC сортировок на реальных статистических моделях и на основе этого установить зависимость между длинной входных данных и временем сортировки для каждого алгоритма. Для реализации построения статистической модели автором была разработана программа «Model1» на платформе Microsoft Visual Studio Express 2013 (яз. C#).
Описание модели
Как видно из общей схемы модели процесса сортировки (рис. 1) на конечный результат сортировки (массив B) влияют два фактора: массив входных значений А и алгоритм сортировки.
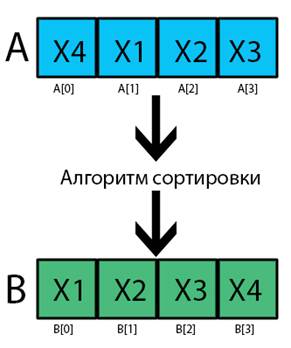
Рисунок 1. Модель процесса
Алгоритм сортировки будет рассматривается в нашем эксперименте как черный ящик, нас не интересует те процессы которые в нём происходят, так как это не входит в тему данной статьи. Однако он содержит 2 интересующих нас выхода: это кол-во операций сравнения (Ncom) и кол-во операций замены (Nrep). Скорость работы алгоритма мы будем измерять по тактам, а не по реально засекаемому таймером временю выполнения. Иными словами, каждый шаг алгоритма будет увеличивать соответствующий счётчик (сравнения, замены). Таким образом мы получим наиболее точную картину работы алгоритма, откинув различного рода «помехи» от действия ОС, программ и физических элементов. Так же для того, чтобы максимально точно определить Ncom и Nrep для последовательностей длинною Lgen, будет произведено кол-во генераций входных данных Pgen раз. Стоит отметить, что в увеличение Pgen позволяет получать наиболее точные результаты, однако на последовательностях длинной Lgen > 1000, время анализа будет крайне велико, поэтому было выбрано оптимальное значение Pgen = 100. Таким образом время работы алгоритма будет представляться в виде 2-х значного контейнера Talg (1).
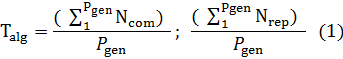
В нашем эксперименте поток входных данных будет параллельно обрабатываться 3-мя алгоритмами сортировки. Иначе говоря набор всех входных данных поступающих на «вход» каждого алгоритма на каждом шаге будет одинаков. Это в свою очередь позволит повысить точность сравнения скоростей алгоритмов между собою.
Результаты эксперимента
Как было отмечено в начале, для построения статистической модели было разработано специальное ПО, позволяющее просчитать огромное кол-во операций сортировок. (рис. 2).
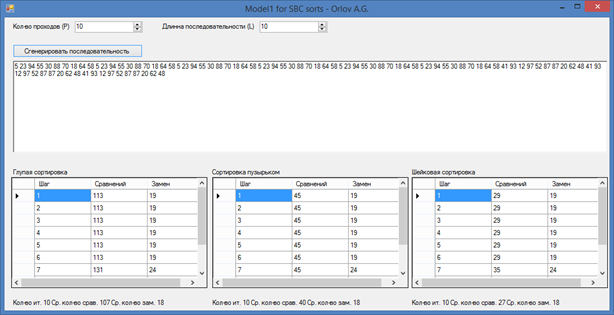
Рисунок 2. Скриншот программы
В программе было предусмотрено введение Pgen — поле «Кол-во проходов» и Lgen — поле «Длина последовательности». В поле чуть ниже отображены все анализируемые последовательности, а в 3-х соответствующих таблицах отображены значения Ncom и Nrep на каждой итерации к соответствующей сортировке. Под каждой таблицей располагаются средние значения Ncom и Nrep, т.е T1alg (T1 — для глупой сортировки), T2alg (T2 — для сортировки пузырьком), T3alg (T3 — для шейкерной сортировки).
Путём последовательного изменения Lgen были сняты значения T1alg[Ncom], T2alg[Ncom], T3alg[Ncom] и построен график. (рис. 3). Так же на основе полученных значений были составлены формулы зависимости Talg от Lgen .
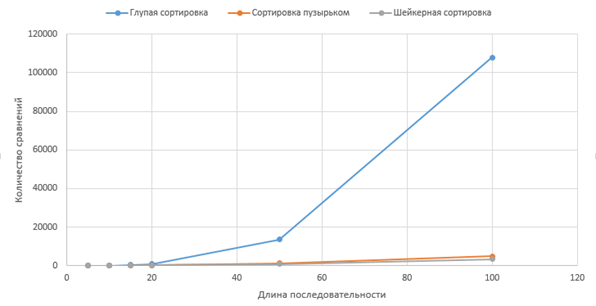
Рисунок 3. Зависимость Talg[Ncom] от Lgen ,
Стоит отметить очень важную особенность, что при любом значении Lgen, Nrep во всех трёх алгоритмах одинаковое(2). Это позволяет сделать вывод, что Nrep можно не учитывать при сравнении Talg (3).
![]()
![]()
Ниже приведены эмпирические формулы расчёта Talg от Lgen полученные в ходе эксперимента. Для того, чтобы повысить точность расчёта для каждой формулы в круглых скобках указано максимально используемое автором значение Lgen.
Для глупой сортировки:
![]()
![]()
Для сортировки пузырьком:
![]()
![]()
Для шейкерной сортировки:
![]()
![]()
Согласно формулами 2,3 можно сделать вывод:
![]()
![]()
Вывод
В ходе эксперимента удалось получить точную формульную зависимость между значением количества элементов массива и скоростью его обработки для каждого SBC алгоритма. За счет обнаруженного равенства Nrep (кол-во замен) во всех случаях, можно сравнивать скорости алгоритмов непосредственно по Ncom (кол-во сравнений). Таким образом был впервые получен универсальный и достоверный критерий сравнения алгоритмов.
Список литературы:
1.Ананий В. Левитин. Глава 3. Метод грубой силы: Пузырьковая сортировка // Алгоритмы: введение в разработку и анализ = Introduction to The Design and Analysis of Algorithms. М.: Вильямс, 2006. — С. 144—146. — ISBN 5-8459-0987-2.
2.Грин Д., Кнут Д. Математические методы анализа алгоритмов. Пер. с англ. М.: Мир, 1987. — 120 с.
3.Макконелл Дж. Основы современных алгоритмов. Изд. 2 доп. М.: Техносфера, 2004. — 368 с. — ISBN 5-94836-005-9.
дипломов