
Статья опубликована в рамках: LIV Международной научно-практической конференции «Технические науки - от теории к практике» (Россия, г. Новосибирск, 25 января 2016 г.)
Наука: Технические науки
Секция: Информатика, вычислительная техника и управление
Скачать книгу(-и): Сборник статей конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
АНАЛИЗ И СРАВНЕНИЕ СУЩЕСТВУЮЩИХ МОДЕЛЕЙ ПРОЦЕССОВ ETL ДЛЯ ХРАНИЛИЩ ДАННЫХ
Талгатова Зарина Талгатовна
главный специалист Отдела Хранилища данных
Управления автоматизации Бэк-офисной деятельности
Департамента Информационных Технологий АО «БанкЦентркредит»,
Республика Казахстан, г. Алматы
E-mail: zarina.talgatova@yandex.ru
ANALYSIS AND COMPARISON OF EXISTING MODELS OF ETL PROCESSES FOR DATA WAREHOUSING
Zarina Talgatova
chief Specialist Data Warehousing Division Automation
of back-office activities Office Information Technology Department
JSC “BankCentercredit”,
Kazakhstan, Almaty
АННОТАЦИЯ
Инструменты извлечение-трансформация-загрузка (ETL) – это часть программного обеспечения, отвечающая за извлечение данных из нескольких источников, очищение, настройку, переформатирование, интеграцию и занесение в хранилище данных. Создание ETL процесса является одной из самых важных задач построения хранилища данных: это сложный и трудоемкий процесс, который занимает много времени, и требует больших усилий. Построение хранилища данных требует четкого понимания трех основных областей: область источника (source), область назначения(target), а также область самого ETL-процесса (mapping). Несмотря на важность ETL-процессов, было проведено мало исследований в этой области. Не существует четкого описания стандартной модели, которая может использоваться для представления сценариев ETL.
В этой статье буде сделана попытка консолидировать все ранее полученные исследования. Исследования в области моделирования ETL процессов можно разделить на три основных подхода: моделирование на основе отображения выражений и руководящих принципов, моделирование на основе концептуальных построений, моделирование на основе UML среды. Эти подходы пытаются представить основные направления деятельности mapping- ов на концептуальном уровне.
ABSTRACT
Extract-transform-load tool (ETL) is a piece of software that is responsible for retrieving data from multiple sources, cleaning, adjustment, reformat, integration and insert into the data warehouse. Create ETL process is one of the most important tasks of building a data warehouse: this is a complex and time-consuming process. Building a data warehouse requires a clear understanding of the three main areas: the source area (source), the area of destination (target), and the scope of the ETL-process (mapping). Despite the importance of the ETL-processes, little research was held in this area. There is no clear description of the standard model, which can be used to represent ETL scenarios.
In this article, the attempt to consolidate all previously received research will be made. Research in the field of modeling ETL processes can be divided into three basic approaches: modeling based on display expressions and guidelines, modeling on the basis of conceptual constructs, UML based modeling environment. These approaches try to present the main activities mapping- items on a conceptual level.
Ключевые слова: хранилище данных(DW), витрины данных (DM), stage-область (DSA), ETL-процесс.
Keywords: Data warehouse (DW), Data marts (DM), Data stage area (DSA), ETL process.
- Введение.
Хранилище данных (DW) – набор технологий, разработанных для СППР (системы поддержки принятия решений). Хранилища данных разительно отличаются от оперативных баз данных.
Архитектура состоит из трех слоев (источники данных, DSA и хранилище данных) [4]. Хотя область ETL-процессов очень важна, она еще недостаточно изучена, потому что существует ряд трудностей и отсутствие формальной модели для представления ETL деятельности, которая бы трансформировала поступающие данные из различных DS в подходящем формате для загрузки в DW или DM [1; 3]. Чтобы построить DW мы должны иметь инструмент ETL, который имеет три задачи:
- извлечение данных из различных источников данных;
- распространяется на промежуточной области данных, где она преобразуется и форматируется;
- загружаются в Хранилище данных.
ETL инструменты – категория специализированных инструментов, которые занимаются очисткой, преобразованием и загрузкой, а также с проблемами, которые возникают в процессе загрузки. Многие научно-исследовательские проекты пытаются представить основные направления деятельности ETL-процессов на концептуальном уровне. Наша цель состоит в том, чтобы провести анализ существующих моделей и выбрать наиболее подходящую модель для дальнейшей разработки.
Статья будет организована следующим образом: В разделе 2 будут обсуждаться концепции ETL моделирования. Описание существующих моделей и сравнительная характеристика будут приведены в разделе 3. В разделе 4 будут подведены итоги и сделаны выводы.
- Понятия ETL моделирования.
Общие рамки для ETL-процессов показаны на рис. 1. Данные извлекаются из различных источников данных, а затем распространяются на DSA, где она преобразуется и очищается перед загрузкой в хранилище данных. Источник, DSA, и целевые среды могут иметь множество различных форматов структуры данных, плоские файлы, базы данных XML, реляционныe таблицы, нереляционные источники, источники веб-журналов, унаследованных систем и электронных таблиц.
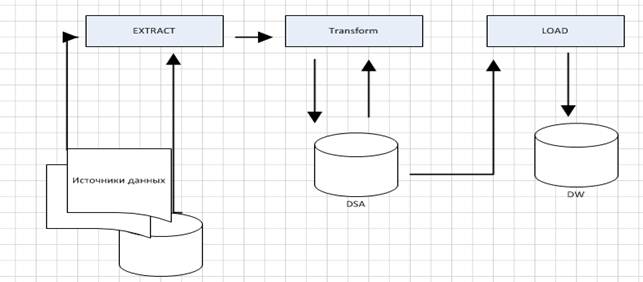
Рисунок 1 Процесс загрузки данных в DW
- Фазы ETL.
В процессе ETL, данные извлекаются из OLTP базы данных, преобразованных в соответствии со схемой хранилища данных, и загружаются в хранилище данных базы данных. Многие хранилища данных также включают в себя данные из систем, отличных от OLTP, таких как текстовые файлы, унаследованных систем и электронных таблиц. ETL – сложное сочетание процессов и технологий, которое требует значительную часть усилий в области развития хранилищ данных и навыков бизнес-аналитиков, проектировщиков баз данных и разработчиков приложений. Процесс ETL не разовое мероприятие. В зависимости от того как изменяются источники данных, информация в хранилище данных будет периодически обновляться. Кроме того, как изменяется бизнес-логика систему DW необходимо менять, для того, чтобы сохранить свою ценность в качестве инструмента для лиц, принимающих решения. Процессы ETL должны быть разработаны для простоты модификации. Хорошо продуманная, и документированная система ETL необходимо для успеха хранилища данных проекта.
Система ETL состоит из трех последовательных функциональных шагов: извлечение, преобразование и загрузка.
- Извлечение.
Первым шагом в любом случае ETL является извлечение данных. Стадия экстракции ETL отвечает за извлечение данных из исходных систем. Каждый источник данных имеет определенный набор характеристик, которые должны управляться, чтобы эффективно извлекать данные для процесса ETL. Процесс должен эффективно интегрировать системы, которые имеют различные платформы, такие как различные системы управления базами данных, различных операционных систем и различных коммуникационных протоколов.
Процесс извлечения состоит из двух фаз, начальной добычи и извлечение измененных данных. В первоначальном извлечении (перегрузка full) [3], это единичная загрузка, которая позволяет загрузить данные полностью, которые впоследствии могут изменяться. Этот процесс осуществляется только один раз после строительства DW, чтобы заполнить его с огромным количеством данных из систем-источников. Инкрементальное извлечение – это извлечение снимка измененных данных (CDC), где процессы ETL обновляют DW данные в соответствии с DS с момента последнего их извлечения. Этот процесс является периодическим в соответствии с циклом обновления и бизнес-потребностями. Он также захватывает только измененные данные с момента последнего извлечения при использовании многих методов в виде столбцов аудита, журнала базы данных, системной даты или технику дельты.
- Преобразование.
Второй шаг в любом ETL является преобразование данных. Шаг преобразования, как правило, существует для того, чтобы привести извлеченные данные в формат, который требуется для загрузки в DW. Этот процесс включает в себя очистку данных, преобразование и интеграцию. Он определяет степень детализации таблицы фактов, таблиц измерений, DW схеме (звезда или снежинка), полученных фактов, медленно меняющихся размеров, factless таблиц фактов. Все правила, преобразования, и полученные схемы описаны в хранилище метаданных.
- Загрузка.
Загрузка данных в целевые многомерные структуры является заключительным этапом ETL. На этом этапе, извлекается и преобразуется данные записываются в мерных структур, которые фактически используется конечными пользователями и прикладных системами. Шаг Загрузка включает в себя как загрузку таблиц измерений, так и загрузку таблиц фактов.
- Существующие модели ETL процессов и сравнительная характеристика.
Хотя процессы ETL имеют решающее значение в создании и поддержании системы DW, есть явный недостаток стандартной модели, которая может быть использована для представления сценариев ETL. Исследования в области моделирования ETL процессов можно разделить на три основных подхода:
- Моделирование на основе сопоставления выражений и руководящих принципов.
- Моделирование на основе концептуальных построений.
- Моделирование на основе UML среды.
В дальнейшем представлено краткое описание каждого подхода.
- Процесс ETL моделирования с использованием mapping expressions.
Данная модель была использована для создания активного инструмента ETL. В своем подходе, запросы используются для достижения процесс складирования. Запросы будут использоваться для представления соответствия между источником и целевой информации; Таким образом, позволяя СУБД играть более значительную роль в качестве двигателя преобразования данных, а также хранилища данных. Такой подход позволяет полностью взаимодействовать между метаданными отображения и инструмента складирование. Кроме того, в нем рассматривается эффективность инструмента ETL на основе запроса хранилища данных, не предлагая никаких графических моделей. Он описывает генератор запросов для повторного использования и более эффективными хранилища данных (DW) обработки.
3.1.1. Руководство соответствий (mapping).
Руководство соответствий означает набор информации, определенной разработчиками для достижения соответствия между атрибутами двух схем. На самом деле, различные виды принципов маппирования используются для многих приложений. Традиционно, эти руководящие принципы определяются вручную во время внедрения системы. В лучшем случае, они сохраняются в виде бумажных документов. Эти руководящие принципы используются в качестве ссылок каждый раз, когда нужно понять, как атрибут целевой схемы был сформирован из атрибутов источников.
3.1.2. Сопоставление выражения.
Отображение выражение атрибута – информация, как целевой атрибут создается из атрибутов источников. Примеры приложений, где отображение выражения используются: отображение схемы для отображения схемы базы данных, выражение отображение необходимы, чтобы определить соответствие между соответствующими элементами.
- Хранилища данных инструмента (ETL) включает в себя процесс трансформации, где определяется соответствие между источниками данных и целевым DW.
- EDI отображение сообщение: необходимость комплексного перевода сообщений требуется для EDI, где данные должны быть преобразованы из одного формата EDI сообщения в другой.
-
EAI (интеграция корпоративных приложений): интеграция информационных систем и приложений нуждается в промежуточном управлении этим процессом. EAI включает в себя правила управления приложениями или иного предприятия, правила разброса данных для приложений, а также правила преобразования данных.
- Моделирование ETL процессов с использованием концептуальных конструкций.
В [4] авторы пытаются представить первую модель по отношению концептуальному моделированию процессов ETL для хранилищ данных. Они вводят рамки для моделирования ETL деятельности. Их структура состоит из трех слоев, как показано на рис. 2.

Рисунок 2 Процесс загрузки данных в DW
Нижний слой, а именно; слой схемы, включает в себя конкретный сценарий ETL. Все объекты слоя схемы являются экземплярами классов типов данных, тип функции, начальная деятельности, записей, и отношений.
Более высокий уровень, а именно; метамодель слой включает в себя вышеупомянутые классы. Связь между метамодели и слои схемы достигается за счет воплощения (“InstanceOf”) отношений. Метамодель уровень реализует вышеупомянутую общности: пять классов, которые участвуют в метамодели слоя достаточно общим, чтобы смоделировать любой сценарий ETL посредством соответствующего экземпляра.
Средний слой является слоем шаблонов. Конструкции в шаблоне слоя, имеют также мета-классы, но они вполне настроены для регулярных случаев ETL-процессов. Таким образом, классы шаблона слоя представляют специализацию (т. е., подклассов) общих классов метамодели слоя (обозначен как “Isa” отношений). Затем они подробно и формально определяют все объекты метамодели:
Типы данных. Каждый тип данных T характеризуется именем и области, которая является счетное множество значений. Значения доменов называют также константами.
- Функции. Тип функции включает в себя имя, конечный список типов данных параметров, а тип возвращаемого значения. Функция является экземпляром типа функции.
- Элементарные мероприятия. Деятельность логические абстракции, представляющие части, или полные модули кода. Используется абстракция исходного кода деятельности, в виде LDL (логически декларативный язык) отчетности, для того, чтобы избежать конфликта с особенностями конкретного языка программирования
3.3. Моделирование на основе UML среды.
В [2] авторы предлагают свою модель, основанную на UML (унифицированный язык моделирования) обозначениях. Известно, что UML не содержит прямого отношения между атрибутами в разных классах, но отношения устанавливаются между самими классами. В своей попытке обеспечить дополнительные виды проектных артефактов в различных уровнях детализации, основа базируется на принципиальном подходе в использовании UML пакетов, для масштабирования в конструкции сценария.
Архитектура хранилища данных обычно изображается в виде различных слоев данных, в котором данные из одного слоя, полученных из данных предыдущего слоя [2]. После этого рассмотрения, разработка DW может быть структурирована в пяти этапов и три уровня, которые определяют различные диаграммы модели DW, как описано ниже:
Пять этапов в определении DW:
- Источник: она определяет источники данных DW, таких как системы OLTP, внешние источники данных.
- Интеграция: определяет соответствие между источниками данных и хранилища данных.
- Хранилище данных: определяет структуру хранилища данных.
- Настройка: определяет соответствие между хранилищем данных и структур клиентов.
- Клиент: определяет специальные структуры, которые используются клиентами для получения доступа в хранилище данных, таких как витрины данных или приложений OLAP.
Уровни:
- Концептуальный: определяет хранилище данных с концептуальной точки зрения.
- Логический: он обращается к логическим аспектам проектирования DW, таким как определение процессов ETL.
- Физическое состояние: он определяет физические аспекты DW, такие как хранение логических структур в разных дисках, или конфигурации серверов баз данных, поддерживающих DW.
3.4 Модели оценки и сравнения.
Таблица 1 содержит матрицу преобразования, используемую для сравнения различных подходов ETL моделирования/
Таблица 1.
Сравнение различных подходов ETL моделирования
|
Критерии оценки |
Модели |
||
|
Использование mapping-выражений |
Использование концептуальных конструкций |
Разработка в UML среде |
|
|
Дизайн |
|||
|
Полноценная графическая модель |
Нет |
Да |
Да |
|
Новые конструкции |
Нет |
Да |
Нет |
|
Независим от DBMS |
Да |
Да |
Да |
|
Mapping-операции |
Да |
Да |
Да |
|
Mapping-отношение |
Да |
Да |
Да |
|
Нереляционный |
Нет |
Нет |
Нет |
|
Преобразующие источники |
Нет |
Нет |
Нет |
|
Плоская модель |
Да |
Да |
Нет |
|
Имплементация |
|||
|
Разработка инструмента |
Да |
Нет |
Нет |
|
Генерация SQL |
Да |
Нет |
Нет |
|
Генерация документации |
Да |
Нет |
Нет |
|
Итого |
7 |
6 |
4 |
- Заключение.
ETL процессы очень важная проблема в текущем исследовании хранилищ данных. В этой статье мы изучили очень важную проблему в текущем исследовании хранилищ данных. Эта проблема представляет собой реальную необходимость нахождения стандартной концептуальной модели для представления в упрощенном виде для извлечения, преобразования и загрузки (ETL-процессов). В данной статье была сделана попытка классифицировать эти подходы на три категории; моделирование на основе отображения выражений и руководящих принципов, моделирование на основе концептуальных построений, моделирование на основе UML среды. Была приведена подробная характеристика каждой из моделей. Также был сделан вывод, что при дальнейшей разработке целесообразно было бы использовать первую модель, поскольку при сравнительном анализе выявились явные премущества даной модели.
Список литературы:
- Dobre A., Hakimpour F., Dittrich K.R., 2003. Operators and classification for data mapping in semantic integration. In: Proceedings of the 22nd International Conference on Conceptual Modeling (ER’03), LNCS, vol. 2813, Chicago, USA, Р. 534–547.
- Trujillo J., Lujan-Mora S., 2003. A UML based approach for modeling ETL processes in data warehouses. In: Proceedings of the 22nd International Conference on Conceptual Modeling. LNCS, Chicago, USA.
- Kimball R., J. Caserta, 2004. The Data Warehouse ETL Toolkit. Practical Techniques for Extracting, Cleaning, Conforming and Delivering Data Wiley.
- Vassiliadis et al., 2002a Vassiliadis P., Simitsis A., Skiadopoulos S., 2002. Conceptual modeling for ETL processes. In: Proceedings of the Fifth ACM International Workshop on Data Warehousing and OLAP.
- Zhang et al., 2008 Zhang, Xufeng, Sun, Weiwei, Wang, Wei, Feng, Yahui, Shi, Baile, 2008. Generating incremental ETL processes automatically. In: IEEE Computer and Computational Sciences, P. 516–521.
дипломов