
Статья опубликована в рамках: LIV Международной научно-практической конференции «Технические науки - от теории к практике» (Россия, г. Новосибирск, 25 января 2016 г.)
Наука: Технические науки
Секция: Информатика, вычислительная техника и управление
Скачать книгу(-и): Сборник статей конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
ПРОГРАММНАЯ БИБЛИОТЕКА ДЛЯ ОБРАБОТКИ ВЫРАЖЕНИЙ ИСЧИСЛЕНИЯ ВЫСКАЗЫВАНИЙ
Караваева Ольга Владимировна
доц. кафедры ЭВМ, Вятский государственный университет,
РФ, г. Киров
E-mail: karavaeva@vyatsu.ru
Долженкова Наталия Алексеевна
студент, Вятский государственный университет,
РФ, г. Киров
E-mail: leto.nataly @gmail.com
SOFTWARE LIBRARY FOR PROPOSITIONAL CALCULUS EXPRESSIONS PROCESSING
Olga Karavaeva
assistant of professor, Vyatka State University,
Russia, Kirov
Natalia Dolgenkova
student, Vyatka State University,
Russia, Kirov
АННОТАЦИЯ
В статье рассматривается структура программной библиотеки, предназначенной для обработки выражений исчисления высказываний. Библиотека содержит функционал, связанный с выполнением лексического и синтаксического анализа выражений в базисе «И-ИЛИ-НЕ», а также некоторые дополнительные возможности по преобразованию – построение совершенных форм, трансляция в строковое представление и так далее. Разработка представлена в открытом доступе и может быть использована в сторонних проектах для решения специфических подзадач.
ABSTRACT
The article discusses the structure of a software library designed to processing expressions of the propositional calculus. The library contains functionality related to the implementation of the lexical and syntactic analysis of expressions in the basis of “AND-OR-NOT”, as well as some additional features to transform expressions – the construction of perfect forms, broadcast to a string, and so on. Development is represented in the public domain and can be used in third-party projects for solving specific tasks.
Ключевые слова: исчисление высказываний; лексический анализ; синтаксический анализ.
Keywords: propositional calculus; lexical analysis; syntactic analysis.
Введение. В современной жизни программисты часто сталкиваются с задачами обработки логических выражений. В большинстве случаев такие задачи являются не самостоятельными, а выступают в роли подзадач, решение которых необходимо для достижения конечного результата, однако выделение сколь-нибудь значимых ресурсов на это не целесообразно [1].
Как правило, процесс обработки любого выражения включает в себя этапы лексического и синтаксического анализа и, возможно, выполнение некоторых действий с полученными в результате этих действий структурами. Реализация первых двух этапов требует от программиста достаточно глубоких знаний в таких областях как теория компиляторов и трансляторов, формальные грамматики и математическая логика. Вместе с тем, создание лексического и синтаксического анализаторов является рутинной работой [2].
В связи с этим, задача разработки универсальной, расширяемой, гибкой и легко подключаемой программной библиотеки, способной выполнять лексический и синтаксический анализ выражений исчисления высказываний, а также осуществлять минимальный набор преобразований над ними, несомненно, является актуальной.
Структура библиотеки. Реализация библиотеки выполнялась с применением объектно-ориентированного подхода с помощью языка программирования Java. Преимуществами данного языка являются, во-первых, его кроссплатформенность, а во-вторых, хорошая совместимость с другими языками программирования. Совокупность данных факторов позволила получить техническое решение, близкое к оптимальному с точки зрения возможности интеграции в существующие проекты.
Предлагаемая библиотека состоит из трех модулей – ExpressionProcessing (обработчик выражений), Tree (инкапсуляция дерева грамматического разбора выражения) и TreeList (инкапсуляция вершины дерева грамматического разбора). Диаграмма классов библиотеки представлена на рисунке 1.

Рисунок 1. Структура программной библиотеки
Точкой входа в библиотеку для сторонних приложений является основной модуль ExpressionProcessing. Он содержит в себе следующие общедоступные методы:
- String[] lexical(String) – метод, осуществляющий разбор исходного выражения, то есть лексический анализ. На вход подается строка, результатом работы метода является массив лексем.
- Tree syntactic(String[]) – метод, осуществляющий синтаксический анализ, то есть построение дерева грамматического разбора (ДГР). На вход этого метода подается массив лексем, полученный в результате работы предыдущего метода, на выходе формируется структура ДГР.
- String getPerfectCNF(Tree) – метод, позволяющий преобразовать заданное выражение в совершенную конъюнктивную нормальную форму. На вход подается сформированное ДГР выражения. На выходе появляется строка, содержащая конъюнкцию элементарных дизъюнкций.
- String getPerfectDNF(Tree) – метод, позволяющий преобразовать заданное выражение в совершенную дизъюнктивную нормальную форму. На вход, как и в предыдущем случае, подается сформированное ДГР выражения. На выходе появляется строка, содержащая дизъюнкцию элементарных конъюнкций.
Модуль Tree, как было отмечено выше, инкапсулирует структуру ДГР, а также содержит в себе набор публичных методов, предназначенных для обработки непосредственно ДГР.
- boolean eval(Map<String, Boolean>) – метод, вычисляющий значение исходного выражения по заданным значениям переменных.
- String toString() – метод, преобразующий ДГР в виде структуры Tree в строку – выражение исчисления высказываний.
Наибольший интерес с точки зрения реализации представляют методы формирования ДГР выражения и построения нормальных форм.
Построение дерева грамматического разбора. Построение дерева грамматического разбора выполняется путем осуществления синтаксического анализа набора лексем, полученных на этапе выполнения лексического анализа заданного выражения.
В общем случае процесс синтаксического разбора осуществляется с использованием форм Бэкуса-Наура (БНФ). Основной компонент грамматики БНФ – это множество правил подстановки в форме LHS –> RHS, где LHS – нетерминальный символ, а RHS – последовательность, в которую входит неотрицательное число символов (терминальных или нетерминальных) [3].
Использованные в данной библиотеке БНФ представлены на рисунке 2.
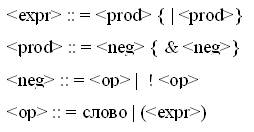
Рисунок 2. Использованные формы Бэкуса-Наура
В соответствии с этим представлением были реализованы закрытые методы, позволяющие выполнить построение ДГР. В данной работе используется рекурсивный предиктивный анализатор [2], в котором все операции со стеком выполняются в неявной форме.
Предиктивный синтаксический анализатор включает в себя: управляющую программу, входной буфер, стек, таблицу разбора и выходной поток. Входной буфер содержит анализируемую строку с маркером ее правого конца – специальным символом.
Предложенные метод характеризуется линейной временной сложностью относительно числа лексем анализируемого выражения.
Построение совершенных форм. Формальное определение конъюнктивной и дизъюнктивной нормальных форм выглядит следующим образом.
СКНФ – нормальная форма, в которой булева формула имеет вид конъюнкции дизъюнкций литералов. СДНФ – нормальная форма, в которой булева формула имеет вид дизъюнкции конъюнкций литералов [1].
Реализации методов построения СКНФ и СДНФ, включенных в рассматриваемую библиотеку, предполагают формирование данных структур по определению посредством полного перебора на основе битовых масок.
Алгоритм преобразования состоит из следующих шагов (на примере СДНФ).
1.Сформировать начальную маску – 00…00. Инициализировать пустую строку результата.
2.Сгенерировать на основе текущей маски карту <, >.
3.Вычислить значение выражения с помощью сгенерированной карты.
4.Если выражение ложно, то перейти к п. 5. В противном случае сформировать строковое представление дизъюнкции переменных, которым были сопоставлены истинные значения, и приписать это представление к строке результата, соединив его символом конъюнкции.
5.Если проанализированы не все маски, то перейти к следующей маске и вернуться к выполнению пункта 2. В противно случае перейти к пункту 6.
6.Алгоритм завершен.
Использованный алгоритм обладает экспоненциальной временной сложностью и может быть использован только в тех случаях, когда в состав анализируемого выражения входят не более 20 различных переменных. Необходимо также отметить, что для хранения получаемых СДНФ или СКНФ требуются весьма значительные объемы памяти. Так, например, строковое представление СДНФ выражения с 20 различными переменными может занимать порядка 200–400 Мб оперативной памяти.
Заключение. Таким образом, в ходе проводимого исследования была спроектирована и реализована программная библиотека для обработки выражений исчисления высказываний. Библиотека находится в свободном доступе по адресу http://www.github.com/ ... и может быть использована в качестве подключаемого компонента, предназначенного для решения специфических задач, при разработке сложных программных систем.
В дальнейшем планируется расширить функциональные возможности библиотеки и реализовать несколько дополнительных методов: преобразование выражения в заданный базис, генерация произвольного выражения, обладающего определенными свойствами, минимизация заданного выражения и так далее.
Список литературы:
1.Андреева Е.В. Московские олимпиады по информатике / Е.В. Андреева, В.М. Гуровиц, В.А. Матюхин – М.: МЦНМО, 2007. – 256 с.
2.Ахо А. Компиляторы: принципы, технологии и инструментарий / А. Ахо, М. Лам, Р. Сети, Д. Ульман. – М.: Издательский дом «Вильямс», 2007. – 1184 с.
3.Вирт Н. Построение компиляторов / Н. Вирт. – М.: ДМК Пресс, 2013. – 192 с.
дипломов