
Статья опубликована в рамках: XXXIII Международной научно-практической конференции «Инновации в науке» (Россия, г. Новосибирск, 28 мая 2014 г.)
Наука: Математика
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
МЕТОД ПОСТРОЕНИЯ N-ГРАММНОЙ МОДЕЛИ АДАПТИРОВАННОЙ ДЛЯ СЛАВЯНСКИХ ЯЗЫКОВ
Тарануха Владимир Юрьевич
ассистент факультета кибернетики Киевского национального университета имени Тараса Шевченко, Украина, г. Киев
E-mail:
AVMETHOD FOR CREATING A N -GRAM MODEL ADAPTED FOR SLAVIC LANGUAGES
Taranukha Volodymyr
assistant, Faculty of Cybernetics, Taras Shevchenko National University of Kyiv, Ukraine, Kyiv
АННОТАЦИЯ
Построена модель для распознавания речи и текстов, которая работает лучше, чем стандартные n-граммные модели, для славянских языков. Проверена возможность применения эвристического морфологического анализа при построении n-граммной модели.
ABSTRACT
A model for speech and text recognition is built. It works better than standard models for Slavic languages. The heuristic algorithm for morphology was tested as an auxiliary tool.
Ключевые слова: n-граммная модель языка; модель на классах; эвристический морфологический анализ.
Keywords: n-gram language model; class-based model; heuristic morphological analysis.
Значительный рост объемов информации в виде цифровых аудиозаписей и изображений текстов требует эффективных средств, позволяющих переводить данные в текстовую форму. Стандартом де-факто является использование статистической модели на основе n-грамм [4]. Однако при ее использовании для славянских языков проявляется ряд недостатков, связанных со свойствами этих языков. Предлагается модификация классической модели с опорой на лексические и грамматические классы.
Построение и оценка моделей
Модель предполагает, что речь обладает свойствами, позволяющими описать ее как марковскую цепь. Последовательность слов языка w1. .. wn называется n-граммой длины n и обозначается ![]() . Вероятность последовательности слов можно оценить как
. Вероятность последовательности слов можно оценить как ![]() , для вероятностей выполняется:
, для вероятностей выполняется: 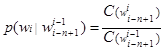 , где
, где ![]() — частота соответствующей n-граммы.
— частота соответствующей n-граммы.
Характерной чертой славянских языков является сравнительно свободный порядок слов в предложениях, и многие слова имеют большое количество словоформ. В словоформах хранится информация, указывающая на потенциальные синтаксические связи слов. Как следствие, значительное количество n-грамм приобретает малые значения частот, и оценка вероятностей становится чувствительной к шумам, мешая достичь таких же высоких показателей распознавания, как для романо-германских языков.
Для оценки качества модели без необходимости проведения эксперимента с распознаванием используется сравнение двух моделей через кросс-энтропию. Пусть ![]() — модель для вероятности
— модель для вероятности ![]() , тогда кросс-энтропия в расчете на слово выражается следующим образом:
, тогда кросс-энтропия в расчете на слово выражается следующим образом: ![]() , для нее известно, что
, для нее известно, что ![]() . Тогда перплексия задается так:
. Тогда перплексия задается так: ![]() .
.
Новый метод повышения качества модели
Предлагается модификация классической модели с опорой на лексические и грамматические классы. Последовательность слов ![]() дает информацию в две различные частичные модели: на основе канонических форм слов и на основе грамматических классов слов. Затем на основе двух моделей строится общая модель, исходя из гипотезы, что для слов, о которых известно, что они имеют одинаковое синтаксическое поведение, можно оценить вероятности n-грамм.
дает информацию в две различные частичные модели: на основе канонических форм слов и на основе грамматических классов слов. Затем на основе двух моделей строится общая модель, исходя из гипотезы, что для слов, о которых известно, что они имеют одинаковое синтаксическое поведение, можно оценить вероятности n-грамм.
Обозначим: ![]() — совокупность последовательностей канонических форм
— совокупность последовательностей канонических форм ![]() ,
, ![]() — совокупность последовательностей грамматических классов
— совокупность последовательностей грамматических классов ![]() ,
, ![]() — совокупность последовательностей слов, которые после приведения к каноническим формам имеют одинаковую запись (совокупность
— совокупность последовательностей слов, которые после приведения к каноническим формам имеют одинаковую запись (совокупность ![]() , таких что,
, таких что, ![]() ). Тогда оценка частоты
). Тогда оценка частоты ![]() определяется:
определяется:
 , (1)
, (1)
где ![]() — соответствующие частоты n-грамм.
— соответствующие частоты n-грамм.
Условие при котором модель будет корректной после перерасчета (псевдо) частот.
![]() , (2)
, (2)
где ![]() — частота соответствующей n-граммы.
— частота соответствующей n-граммы.
Вопрос обеспечения достоверности объединенной модели исследован в [3].
Метод сглаживания
Для сглаживания и заполнения пропусков используются различные методы [4], в данной статье рассматривается сглаживание с возвращением Виттена-Белла, поскольку оно включает все необходимые параметры.
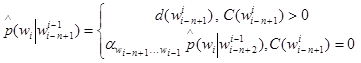 , (3)
, (3)
где ![]() — соответствующим образом сглаженное значение
— соответствующим образом сглаженное значение ![]() ,
,![]() — коэффициент вероятностной массы, перераспределенной для построения вероятностей на n-граммах модели меньшего порядка.
— коэффициент вероятностной массы, перераспределенной для построения вероятностей на n-граммах модели меньшего порядка.
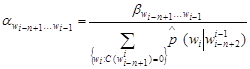 , (4)
, (4)
![]() , (5)
, (5)
Для метода Виттена-Бела параметр d оценивается следующим образом:
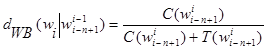 , (6)
, (6)
где ![]() — количество типов n-грамм, предшествующих слову wi.
— количество типов n-грамм, предшествующих слову wi.
После применения формулы (1) n-граммы получат не частоты, а псевдочастоты. Сглаживание по формуле Виттена-Бела удобно, поскольку не требуется регулировать, от какого значения псевдочастоты необходимо начислять элементы в ![]() . Метод Катца с возвращением не подходит, поскольку опирается на эвристику Гуда-Тьюринга [4], которая не имеет понятного способа интерпретации, если вместо частот в нее подставить псевдочастоты. Возможно применение других методов, но оно потребует дополнительного анализа.
. Метод Катца с возвращением не подходит, поскольку опирается на эвристику Гуда-Тьюринга [4], которая не имеет понятного способа интерпретации, если вместо частот в нее подставить псевдочастоты. Возможно применение других методов, но оно потребует дополнительного анализа.
Вспомогательный инструмент
Применялся расширенный алгоритм определения грамматических свойств неизвестных слов [1]. Он опирается на набор биграмм, полученный из корпуса.
Грамм-код ![]() — идентификатор, который однозначно описывает всю совокупность грамматических признаков словоформы w.
— идентификатор, который однозначно описывает всю совокупность грамматических признаков словоформы w. ![]() — преобразование
— преобразование ![]() к грамм-коду
к грамм-коду ![]() .
. ![]() — вектор частот n-грам, которые отвечают комбинациям
— вектор частот n-грам, которые отвечают комбинациям ![]() , где i перебирает все номера слов в словаре.
, где i перебирает все номера слов в словаре.
Расширений алгоритм эвристического анализа(ЭА):
1. Вычислить признаки по базовым алгоритмам ЭА[2] ![]() , получить различные множества грамм-кодов. Образуются тройки
, получить различные множества грамм-кодов. Образуются тройки ![]() , где i — номер соответствующих параметров запуска.
, где i — номер соответствующих параметров запуска.
2. Для каждой неизвестной словоформы w, для всех значений i, вычисляется элемент, который соответствует грамматическим признакам, полученным от ![]() . Обозначим его
. Обозначим его ![]() .
.
3. Выбирается ![]() , такой что для
, такой что для ![]() :
:![]() &
&![]()
4. Вычисляется косинус угла между ![]() и
и ![]() .
.
5. Максимальное значение указывает на лучший результат анализа.
Расширенный алгоритм показывает значение меры ![]() =0,9, в сравнении с
=0,9, в сравнении с ![]() =0,87 для базового алгоритма.
=0,87 для базового алгоритма.
Численные эксперименты
Эксперименты были проведены на n-граммах размерности ![]() 3, собранных из корпуса стенограмм Верховной Рады Украины объемом 112,5 МБ. Стенограммы были собраны с сайта http://rada.gov.ua/meeting/stenogr. Оценка качества производилась с кросс-валидацией: для построения модели использовались 75 % от корпуса, для вычисления энтропии и перплексии использовалась остальные 25 %. В корпусе были выделены словари из 10.000 и 6.000 словоформ, остальные слова были заменены на стоп-слово "#". Словари были пропущены через систему лексического анализа, были сформированы словари канонических форм и словари грамматических классов. (Классом называется элемент, который однозначно определяет совокупность признаков части речи и саму часть речи заданной словоформы.) Был использован алгоритм для определения характеристик неизвестных слов [1]. Анализ показал, что не для всех слов получены классы, совместимые с уже наличествующими в системе. Потому он пригоден только в небольшом подмножестве случаев.
3, собранных из корпуса стенограмм Верховной Рады Украины объемом 112,5 МБ. Стенограммы были собраны с сайта http://rada.gov.ua/meeting/stenogr. Оценка качества производилась с кросс-валидацией: для построения модели использовались 75 % от корпуса, для вычисления энтропии и перплексии использовалась остальные 25 %. В корпусе были выделены словари из 10.000 и 6.000 словоформ, остальные слова были заменены на стоп-слово "#". Словари были пропущены через систему лексического анализа, были сформированы словари канонических форм и словари грамматических классов. (Классом называется элемент, который однозначно определяет совокупность признаков части речи и саму часть речи заданной словоформы.) Был использован алгоритм для определения характеристик неизвестных слов [1]. Анализ показал, что не для всех слов получены классы, совместимые с уже наличествующими в системе. Потому он пригоден только в небольшом подмножестве случаев.
В результате словари и метод кодировки грамматических классов были переработаны [4], чтобы уменьшить нарушение условия достоверности (2), с учетом результатов, полученных в работе [2]. В словарь системы подбирались не словоформы с высокой частотой, а группы словоформ с высокой средней частотой, при этом собранные по всему корпусу, а не только по 75 % выделенных строк (но n-граммы в модель отбирались только по заданным 75 % корпуса). При определении кодов была выполнена разбивка грамматических признаков и в код класса внесен номер группы флексий, к которой относится окончание. Все слова, имеющие омонимы в словоформах, не менялись на коды, так же как и служебные слова. Предпринятые меры позволили минимизировать нарушения условия (2), но не ликвидировали нарушение полностью. Фильтрация применялась ограниченно, только для триграмм. Для этого из базы триграмм были изъяты триграммы, которые имели частоту 1 и были построены по формуле 1. Те же триграммы, которые состояли из неизмененных слов, не удалялись. Результаты оценки моделей представлены в Таблице 1.
Таблица 1.
Оценка энтропии и перплексии
|
|
Энтропия |
Перплексия |
|
Обычное сглаживание 10 тыс. |
6.9295 |
121,89 |
|
Перераспределение 10 тыс. |
6.906 |
119,92 |
|
Обычное сглаживание 6 тыс. |
6.4476 |
87,28 |
|
Перераспределение 6 тыс. |
6.4344 |
86,48 |
Заметная разница между результатами в Табл. 1 и результатами в [2] обусловлена еще и тем, что словарь в 10 тысяч слов состоит не из самых частотных слов, зато имеющих максимум словоформ.
Также следует отменить уменьшение размера базы n-грамм для больших словарей. Результаты представлены в Таблице 2.
Таблица 2.
Сжатие
|
Ограничения на построение n-грамм |
Биграммы |
Триграммы с учётом фильтрации |
Всего |
|
Словарь 10 тыс. |
1185 тыс. |
4369 тыс. |
5554 тыс. |
|
Словарь 10 тыс., переоценка |
1064 тыс. |
3345 тыс. |
4409 тыс. |
|
Словарь 6 тыс. |
816 тыс. |
3471 тыс. |
4287 тыс. |
|
Словарь 6 тыс., переоценка |
887 тыс. |
2697 тыс. |
3584 тыс. |
Структура данных и результаты сжатия позволили разработать и придали смысл алгоритму, который строит перераспределенные псевдочастоты без генерации всех промежуточных форм n-грамм.
Выводы
Показано, что перераспределение с помощью разработанного метода улучшает показатели перплексии, что позволяет утверждать об ожидаемом улучшении распознавания. Также такое перераспределение позволяет уменьшить размер модели языка. Показано, что наблюдаемое нарушение условий достоверности [3] оставляет место для дальнейшего прироста качества модели, если указанное нарушение устранить полностью.
Проверена работа эвристического морфологического анализа в задаче сглаживания, и показано, что та небольшая часть слов, для которых он полезен, слабо влияет на эффект сглаживания.
Таким образом, получена адаптированная для славянских языков n-граммная модель, и есть метод ее эффективного использования в системах распознавания речи и изображений.
Список литературы
1.Тарануха В.Ю. Евристичний алгоритм морфолексичного аналізу для невідомих слів Праці дев'ятої міжнародної науково-практичної конференції з програмування „УкрПРОГ’2014” , м. Київ, 20—22 травня , 2014. — C. 279—285.
2.Тарануха В.Ю. Застосування класів, основаних на канонічних формах слів та на граматичних класах у задачі редукції n-грамної моделі мови для розпізнавання української мови ./Тарануха В.Ю.// Вісник Київського національного університету імені Тараса Шевченко Серія: фізико-математичні науки. 2013, Спецвипуск. — С. 176—179.
3.Тарануха В.Ю. Модифікація n-грамної моделі, заснованої на класах, для розпізнавання слов’янських мов /Тарануха В.Ю.// Вісник Київського національного університету імені Тараса Шевченко Серія: фізико-математичні науки. — 2014. — Вип. 1. — С. 193—196.
4.Jurafsky D. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition /Daniel Jurafsky, James H. Martin // Prentice Hall PTR Upper Saddle River, NJ, 2000, ISBN:0130950696, — 934 p.
дипломов