
Статья опубликована в рамках: XLIV Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 26 июля 2016 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
дипломов
СРАВНЕНИЕ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ФРЕЙМВОРКА APACHE SPARK И ТЕХНОЛОГИИ WORD2VEC

Аннотация
В данной статье рассматриваются возможные методы анализа больших объемов слабоструктурированной информации, в частности, сравнение документов. Для этого используются генерирующая векторное представление слов модель Word2Vec, фреймворк обработки больших данных Apache Spark, а также библиотеки языка Python для обработки текста.
Введение
Развитие сети Интернет, мобильных устройств, относительная дешевизна хранения данных, – всё это ведет к постоянному увеличению количества хранимой информации. В связи с этим возникает потребность в разработке новых методов и технологий, которые позволили бы обрабатывать большие объемы данных автоматически. Именно для этого был создан фреймворк Apache Spark, в состав которого входят библиотеки, позволяющие структурировать данные, писать к ним SQL запросы, использовать алгоритмы машинного обучения и др.
Одной из задач, в которых требуется автоматическая обработка больших объемов слабоструктурированных данных, является поиск наиболее подходящих друг другу пар соискатель-работодатель. В таких данных, обычно, есть общая структура (документ разделен на секции, например, опыт соискателя), однако информация внутри каждой из секций записана в свободном формате. В отличие от подходов, основанных на поиске ключевых слов, можно использовать модель Word2Vec и анализировать текст документа полностью.
Word2Vec — это набор моделей, принимающих на вход текст и возвращающих представление слов в векторном пространстве на основе контекста [2]. Эти модели (Continous-Bag-Of-Words и skip-gram) представляют собой нейронную сеть, задачей которой является реконструкция контекста слов. Так, задача CBOW – предсказание слова на основании контекста, а задача skip-gram – предсказать контекст на основе единственного слова. Их архитектуру можно посмотреть на рисунке 1.

Рис. 1 Архитектура CBOW и skip-gram
Размер векторного пространства Rn задается вручную, обычно n находится в диапазоне от 500 до 1500. Таким образом, Word2Vec имеет неоспоримое преимущество перед методами, работающими со словарями, – небольшая размерность векторов.
Принцип работы Word2Vec можно описать следующим образом: максимизация косинусной близости 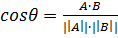 для векторного представления слов, которые появляются в похожих контекстах, и, наоборот, её минимизация для слов, не встречающихся в похожих контекстах.
для векторного представления слов, которые появляются в похожих контекстах, и, наоборот, её минимизация для слов, не встречающихся в похожих контекстах.
После того, как векторные представления получены, появляется возможность, например, находить близость между двумя словами, получать список наиболее близких элементов в векторном пространстве и так далее. Это позволяет избавиться от работы по составлению списков с синонимами для каждого слова. Кроме того, можно получать вектора для целых предложений, используя, например, усредненный вектор всех слов в нём.
Для Apache Spark реализация Word2Vec находится в библиотеке MLlib [3].
Итак, для решения задачи о поиске наиболее подходящих друг другу пар соискатель-работодатель можно выделить следующие этапы:
- Сбор данных;
- Обработка данных;
- Создание модели;
- Определение связей между сущностями.
Сбор и обработка данных
Для того чтобы проверить работу системы, с сайта hh.ru была собрана необходимая информация: около 50000 резюме и 50000 вакансий двух профессиональных областей. Данные сохраняются в формате JSON. Основной проблемой является то, что некоторые поля, например, требования и условия работодателей, никак не выделены. Поэтому каждый документ нужно обработать:
- Выделить секции в документе;
- Разбить каждую секцию на предложения;
- Каждое предложение очистить от html-тэгов и пунктуации и разбить на слова и привести к нижнему регистру;
- Применить стемминг.
Из резюме и вакансий, в которых были явно указаны ключевые навыки, они были извлечены.
Создание модели
Информацию о рекомендуемых для обучения такой модели данных можно найти в статье [1]. Собранных данных немного, но их достаточно для проверки работоспособности прототипа. После того, как документы были обработаны и приведены к нужному виду, весь корпус был подан на вход модели Word2Vec. Результатом стало векторное пространство, элементы которого были расположены в соответствии с определенными ранее условиями. Пример можно увидеть на рисунке 2.
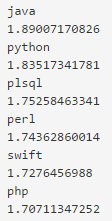
Рис. 2 Элемент java и его соседи
Кроме того, была подтверждена возможность сравнения фраз и предложений с другим словом или фразой. Для этого фраза представляется усредненным вектором всех слов в ней.
Для полученных векторов применялась кластеризация методом Kmeans [4]. Её целью была группировка слов, встречающихся в похожих контекстах, а, следовательно, в одном и том же поле документа. Это позволяет в дальнейшем фильтровать малозначимые слова, задавая для них, например, определённый вес. В результате такой обработки были выделены следующие кластеры (пример на рисунке 3):
- Векторы слов, описывающих профессиональную область;
- Векторы слов, описывающих навыки кандидатов;
- Векторы слов, описывающих личные качества кандидатов;
- Векторы слов, описывающих условия работы, например, з/п, офис и т. д.;
- Векторы слов, не представляющих особой важности.
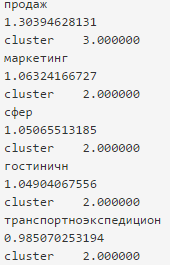
Рис. 3 Принадлежность слов кластерам
Для того чтобы снизить количество сравнений, навыки, необходимые для определенной вакансии, а также сами документы, были разбиты на профессиональные категории, что привело к уменьшению размерности задачи (Например, кандидату на вакансию программиста не будет предложена вакансия официанта). Кроме того, там, где это было возможно, предложениям в документах был присвоен класс, указывающий на их принадлежность определенным блокам: требования, условия, информация о себе и т. д.
Определение связей между сущностями
После обработки как структурированных, так и не структурированных полей, можно построить списки предпочтений. Для этого нужно рассмотреть и сравнить всевозможные пары документов внутри полученных ранее категорий. Для каждого предложения соответствующего поля строится вектор из поэлементной суммы векторов слов, также поэлементно разделенный на количество этих слов. Затем между каждой парой таких векторов резюме и вакансий находится косинусная близость. Вектора слов можно также сравнивать между собой, учитывая веса, определенные для кластеров. Если для данных документов указана принадлежность предложений к определенному полю, то финальная оценка также вычисляется на основе ранее определенных весов. На основании полученной метрики каждой пары предложений, ставится финальная оценка «похожести» резюме и вакансии. Если она переходит определенный порог, то документ добавляется в список предпочтений соответствующего документа другого множества.
Заключение
На основе полученных результатов можно заявить, что метод нахождения связей между соискателями и работодателями, рассмотренный в данной работе, довольно хорошо справляется со своей задачей. В случае, когда имеется большое количество текстовых данных без какой-либо обучающей выборки, использование векторного представления для слов и предложений имеет неоспоримое преимущество. С его помощью можно, не проводя перед этим сложную обработку данных, разбить документы на заранее определенные классы. Точность данной модели является допустимой для решения рассмотренной здесь задачи. Прототип системы был реализован с помощью модуля pyspark фреймворка Apache Spark, его библиотеки MLlib, а также библиотек языка Python: PyStemmer и NLTK.
Список литературы:
- Clustering - spark.mllib - Spark 1.6.2 Documentation – [Электронный ресурс] – Режим доступа. – URL:http://spark.apache.org/docs/latest/mllib-clustering.html (дата обращения 21.07.2016)
- Feature Extraction and Transformation - spark.mllib - Spark 1.6.2 Documentation – [Электронный ресурс] – Режим доступа. – URL: http://spark.apache.org/docs/latest/mllib-feature-extraction.html (дата обращения 21.07.2016)
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean. Distributed Representations of Word and Phrases and their Compositionaly // In Proceedings of Workshop at The Twenty-seventh Annual Conference on Neural Information Processing Systems (NIPS) – 2013 – [Электронный ресурс] – Режим доступа. – URL:http://arxiv.org/abs/1310.4546 (дата обращения 21.07.2016)
- Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space // In Proceedings of Workshop at International Conference on Learning Representations (ICLP) – 2013 – [Электронный ресурс] – Режим доступа. – URL:http://arxiv.org/abs/1301.3781 (дата обращения 21.07.2016)
дипломов