
Статья опубликована в рамках: XIX Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 15 апреля 2014 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

ЯЗЫКОВОЕ МОДЕЛИРОВАНИЕ НА ОСНОВЕ МОРФОВ ДЛЯ СИСТЕМ РАСПОЗНАВАНИЯ РУССКОЙ РЕЧИ
Коробейников Максим Анатольевич
магистрант 2 курса, кафедра АСОИУ ИжГТУ, РФ, г. Ижевск
E-mail:
Мокроусов Максим Николаевич
канд. техн. наук, доцент ИжГТУ, РФ, г. Ижевск
Постоянно растущие возможности вычислительных техники и сетевых технологий уже сейчас не используются в полной мере из-за отсутствия полноценного взаимодействия человека и компьютера на естественном языке. Значимым направлением в решении этой проблемы является автоматическое распознавание слитной речи.
Распознавание слитной речи — это процесс преобразования естественно произнесенных предложений в текст. Такое распознавание сложно тем, что границы отдельных слов не четко определены и их произношение сильно искажено «смазыванием» произносимых звуков.
Кроме того, русская речь трудна для распознавания вследствие своей флективности: из-за наличия большого числа словоформ каждой парадигмы слова объем словаря распознавания и число существующих внесловарных слов возрастают на порядок по сравнению с аналитическими языками [2]. Более того, словарь огромных размеров может привести к путанице в определении акустически подобных слов, и потребуется огромное количество текстовых данных для надежной оценки модели языка, а для русского языка нет статистически или эвристически представительной выборки текстов для построения такой языковой модели.
В данной работе рассматривается возможность разложения базовых элементов языковой модели (самостоятельных слов) на составляющие их значимые единицы с точки зрения распознавания речи (т.н. подслова). Эти единицы используются в качестве элементов словаря для n-граммной модели [1] (рисунок 1). Сегментация слов основана на выделении в тексте морфемноподобных единиц (статистических морфов), из которых состоят слова, по принципу MDL (Minimum Description Length) [5]. Таким образом, можно модифицировать исходный текстовый корпус (рисунок 2) и на его основе построить языковую модель [3], где каждым элементом n-граммы будет не явное слово, а его составная единица — морф. После того, как набор морфов (модель сегментации — МС) получен из некоторого набора текстовых данных, он может быть использован для сегментации новых словоформ в другом произвольном тексте. В этом случае для того, чтобы убедиться, что всегда есть, по крайней мере, один из возможных вариантов сегментаций, каждый отдельный символ в слове, не существующий как морф в текущей МС, может быть предложен в качестве морфа с очень низкой вероятностью.

Рисунок 1. Схема распознавания. АМ — акустическая модель, ЯМ — языковая модель
В дальнейшем при оценке надежности разных языковых моделей для избегания разночтений, будем использовать термин «слово» для обозначения базовых элементов языковой модели и словарей распознавания.

Рисунок 2. Сегментирование текстового корпуса
Для оценки результатов было создано 2 языковые модели (классическая n-граммная модель и модель на основе морфов) из текстового корпуса, представленного 987 тыс. слов. Языковые модели были преобразованы в формат, пригодный для движка распознавания PocketSphinx [3]. Для удобства тестирования моделей и оценке надежности распознавания была разработана программная среда-оболочка, позволяющая получать как аналитические, так и практические (непосредственное распознавание с микрофона или из файла) результаты (рисунки 3, 4).
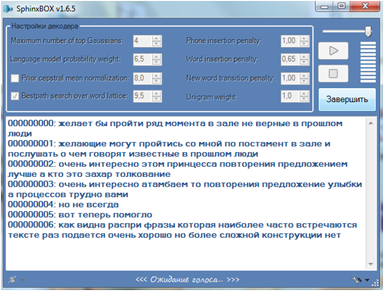
Рисунок 3. Интерфейс среды распознавания. Процесс распознвания.

Рисунок 4. Интерфейс среды распознавания. Выпадающие меню
При сравнении словарей распознавания учитывались их размер (количество составляющих текст уникальных слов) и процент слов, встречающихся 2 или более раза, от всех слов словаря (таблица 1).
Таблица 1.
Показатели словарей распознавания моделей
|
|
Классическая модель |
Модель на основе морфов |
|
Размер словаря |
~104 тыс. |
~40 тыс. |
|
Количество (%) слов, встречающихся не менее 2 раз |
~51 тыс. (49 %) |
~37 тыс. (92 %) |
|
Количество (%) слов, встречающихся не менее 3 раз |
~33 тыс. (32 %) |
~32 тыс. (80 %) |
|
Количество (%) слов, встречающихся не менее 4 раз |
~25 тыс. (24 %) |
~28 тыс. (70 %) |
Таким образом, модель на основе морфов позволила сократить размер словаря на 60 %. Кроме того, для классической модели характерно распределение слов согласно закону Ципфа: лишь малое число слов в языке используется чаще всего, а большее число слов используется крайне редко. Однако для модели на основе морфов удалось повысить охват текста, что видно из данных таблицы. Для текста почти в 1 млн. слов понадобился словарь в 100 тыс. слов, а для модели с морфами в качестве слов понадобилось только 40 тыс.
Для оценки надежности был использован коэффициент показателя связности (ПС) с помощью инструментария CMUclmtk [4]. Заметим, что при фиксированном языке ПС позволяет сравнивать различные языковые модели, а при фиксированном типе модели — оценивать сложность самих естественных языков, и как следствие, часто применяется для конкретной системы распознавания.
Для расчета ПС также необходим и представительный корпус текста. В качестве такового использовался текст книги «Роза Мира» Д. Андреева. Для оценки модели на основе морфов «Роза мира» была предварительно обработана алгоритмом сегментации слов по морфам созданной МС. Результата проверки ПС для обеих моделей представлены в таблице 2.
Таблица 2.
Показатели связности моделей по отношении к тексту книги
|
|
Классическая модель |
Модель на основе морфов |
|
Всего слов в тексте |
~425 тыс. |
~1220 тыс. |
|
ПС |
234,47 |
135,12 |
|
Количество внесловарных слов |
~115 тыс. (27,13%) |
~184 тыс. (15,11 %) |
|
Количество (%) совпадения 3-грамм |
~227 тыс. (53,56 %) |
~902 тыс. (73,97 %) |
|
Количество (%) совпадения 2-грамм |
~52 тыс. (12,41 %) |
~219 тыс. (17,98 %) |
|
Количество (%) совпадения 1-грамм |
~13 тыс. (3,05 %) |
~24 тыс. (1,94 %) |
Данные ПС отражают в частности, что почти 1/3 слов эталонного текста не представлена в классической языковой модели. Модель на основе морфов содержит чуть меньше 1/6 внесловарных слов.
Единственный показатель, по которому классическая модель опередила морфемноподобную — количество совпавших 1-грамм. Объяснение этому видится в следующем: совпадение 1-грамм в данном контексте означает совпадение предложений, состоящих из одного слова. Следовательно, для модели на основе морфов многие предложения из одного слова, например «Сверкалось», разделялись на морфы («Сверка лось»), и уже рассматривались как минимум биграммами, т. е. состоящими по крайней мере из двух «слов».
Таким образом, разложение базовых элементов языковой модели на статистические морфы дает лучшую надежность распознавания и требует меньших затрат ресурсов по сравнению с грамматическим способом разложения. Такой подход пригоден для создания приемлемых тематических языковых моделей (для распознавания спонтанной речи из определённой предметной области), уменьшая необходимый репрезентативный объем базы текстового корпуса. При этом используются преимущества современных статистических методов распознавания, в частности, скрытые марковские модели, что позволяет провести моделирование пригодной для реальной эксплуатации системы распознавания.
Список литературы:
1.Реализация конструирования N-грамм и генерации псевдо ЕЯ-текста на их основе на языке Haskell // Habrahabr : [cайт]. [2013]. [Электронный ресурс] — Режим доступа. — URL: http://habrahabr.ru/post/135127/ (дата обращения 23.06.13).
2.Холоденко А.Б. О построении статистических языковых моделей для систем распознавания русской речи [Электронный ресурс] // Официальный сайт кафедры Математической теории интеллектуальных систем механико-математического факультета МГУ : [cайт]. [2013]. [Электронный ресурс] — Режим доступа. — URL: http://www.intsys.msu.ru/invest/speech/articles/rus_lm.htm (дата обращения 13.02.13).
3.Building Language Model (указания к построению статистических языковых моделей) // Open Source Toolkit For Speech Recognition : [cайт]. [2013]. [Электронный ресурс] — Режим доступа. — URL: cmusphinx.sourceforge.net/wiki/tutoriallm (дата обращения 23.05.13).
4.Documentation for the CMU Sphinx speech recognition engines : [cайт]. [2013]. [Электронный ресурс] — Режим доступа. — URL: http://cmusphinx.sourceforge.net/wiki/ (даты обращения 15.11.12, 9.06.13).
5.Mathias Creutz and Krista Lagus. Unsupervised Morpheme Segmentation and Morphology Induction from Text Corpora Using Morfessor. Publications in Computer and Information Science, Report A81, Helsinki University of Technology, 2005.
дипломов