
Статья опубликована в рамках: I Международной научно-практической конференции «Научное сообщество студентов: МЕЖДИСЦИПЛИНАРНЫЕ ИССЛЕДОВАНИЯ» (Россия, г. Новосибирск, 06 декабря 2011 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов
РАЗРАБОТКА АЛГОРИТМИЧЕСКОГО ОБЕСПЕЧЕНИЯ СИСТЕМЫ АВТОМАТИЗИРОВАННОГО АНАЛИЗА И КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ СИСТЕМ МГНОВЕННОГО ОБМЕНА СООБЩЕНИЯМИ

Системы мгновенного обмена сообщениями являются одним из средств коммуникации как для использования в домашней сети, так и в корпоративной [1]. Массовость использования систем мгновенного обмена сообщениями обусловлена получением информации в течение короткого времени.
Исследование, проведенное крупнейшим изданием в сфере высоких технологий CNews, выявило влияние использования систем мгновенного обмена сообщениями на информационную безопасность предприятия [2]. Бесконтрольное использование систем мгновенного обмена сообщениями может быть источником следующих угроз информационной безопасности:
- снижение эффективности труда сотрудников (46% пользователей используют системы мгновенного обмена сообщениями для личного общения);
- утечка конфиденциальной корпоративной информации (46% пользователей передают конфиденциалую информацию через системы мгновенного обмена сообщениями);
- распространение большого количества сообщений (спама) и вредоносного программного обеспечения (червей и вирусов);
- возможность несанкционированного доступа в сеть.
- Для повышения уровня информационной безопасности на предприятии необходимо осуществлять контроль (мониторинг) за информацией, передающейся через системы мгновенного обмена сообщениями. Контроль заключается в анализе и классификации данных (контента) систем мгновенного обмена сообщениями.
В целях осуществления мониторинга за контентом систем мгновенного обмена сообщениями необходимо разработать алгоритмическое обеспечение системы автоматизированного анализа и классификации данных, которое позволит повысить эффективность методов обнаружения утечки конфиденциальной информации предприятия по каналам данного типа. Структурная схема системы автоматизированного анализа и классификации данных в соответствии с рисунком 1. Таким образом, разработка алгоритмического обеспечения автоматизированного анализа и классификации данных систем мгновенного обмена сообщениями и исследование его эффективности процесса является актуальной научно-практической задачей.
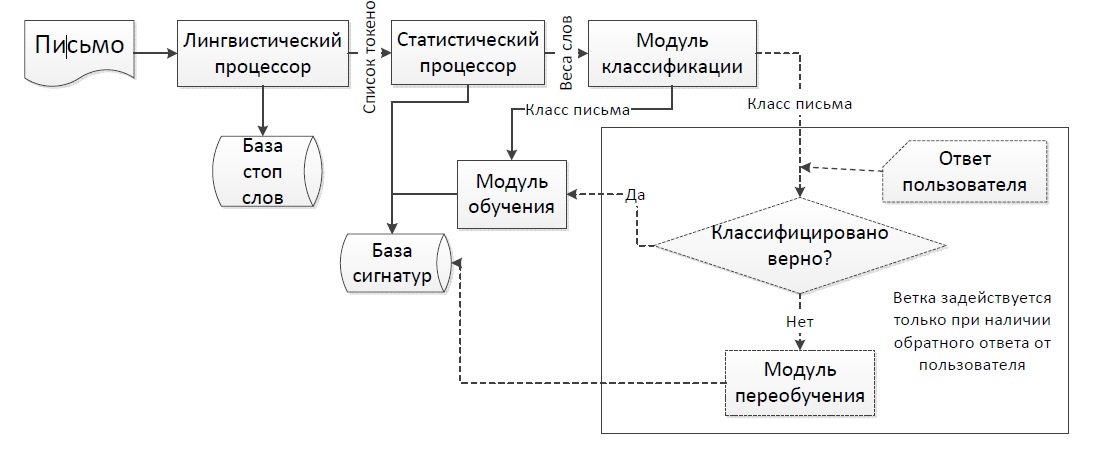
Рисунок 1. Cтруктурная схема системы автоматизированного анализа и классификации данных
Принцип действия разрабатываемого алгоритмического обеспечения основан на применении байесовского фильтра, использующего в своей основе теорему Байеса [3]. Для эффективной работы фильтр необходимо первоначально обучить на большом количестве сообщений IM систем (не менее 1000 сообщений, состоящих из 5 — 25 слов каждое). При обучении фильтра для каждого слова в сообщении высчитывается и сохраняется его вес — вероятность того, что сообщение с этим словом может относиться к конфиденциальной информации. Вычисление веса слова осуществляется по формуле «появлений в конфиденциальном сообщении / появлений всего в сообщениях». После вычисления весов всех слов считается вес самого сообщения как среднее значение весов всех его слов. Отнесение сообщения к конфиденциальному сообщению производится при превышении веса сообщения установленного порога. Информация о словах и их весах хранится в базе данных, которая постоянно обновляется после принятия решения по очередному сообщению.
Байесовский алгоритм эффективно работает только с текстовыми сообщениями, состоящих из правильно написанных слов. Однако специфика общения в системах мгновенного обмена сообщениями заключается в использовании графических объектов («смайлики»), символов вместо букв (например, вместо «а» используется «@»), неправильного или сокращенного написание слов, использование сленговых слов. Поэтому перед анализом и классификацией контента систем мгновенного обмена сообщениями необходимо провести предобработку сообщений, используя алгоритмы замены и лемматизации.
Алгоритм замены заключается в посимвольном анализе всего сообщения и сравнении кода текущего считанного символа с базой данных возможных замещающих символов (например, «а» и «@»). В случае совпадения, замещающий символ заменяется на букву.
Основная идея алгоритма лемматизации — сравнение двух слов, начиная с первой буквы, и нахождение величины совпавшей части. Если величина общей части слов не ниже порогового значения, то рассматриваемые слова считаются родственными. Под порогом понимается критерий, по которому определяется, являются ли две лексемы словоформами одного и того же слова. Критерием для сравнения слов может служить либо число совпавших букв, либо процент совпавших букв в этих словах. Порог подбирается экспериментально. Для нахождения оптимального значения порога необходимо обработать словари большого объема [6].
Основная часть алгоритма лемматизации состоит в извлечении из текста слов, объединении их в группы родственных слов и, наконец, выделении в каждой группе совпадающих (основ) и несовпадающих (кортежей) частей.
Разбиение исходного словаря на группы происходит следующим образом: последовательно берется в качестве входной информации слово из исходного словаря, которое ещё не отнесено ни к одной из полученных групп, и заносит его в группу, к словам которой оно подходит по порогу. Если же такой группы не обнаружено, формируется новая группа, состоящая только из текущего слова. Когда весь исходный словарь будет обработан, группы, состоящие из одного слова, объединяются в одну (нулевую) группу — одиночные слова.
Полученную информацию можно использовать в дальнейшем для формирования множеств основ с тождественными кортежами, отношений включения между ними, а также для формирования парадигм — множеств кортежей, с помощью установления отношений включения между кортежами. В парадигмы должны объединиться слова, имеющие одинаковые окончания в одинаковых формах (например, существительные одного склонения). Планируется также реализовать часть алгоритма, которая будет, исходя из распределения частот встречи каждой формы одного слова в тексте, ставить в соответствие основе некоторое значение (например, обстоятельство места, обстоятельство времени, обозначение предмета и т.д.).
Исходные данные для алгоритма лемматизации должны быть представлены в виде текстового файла. Полученные во время работы данные хранятся в таблицах базы данных.
Новизна идеи основана на использовании алгоритма предварительной обработки сообщений, которые состоят из сленговых слов и замещающих символов. Улучшение качества результата предварительной обработки сообщений приводит к более качественному анализу и классификации данных систем мгновенного обмена сообщениями [9]. Для уменьшения процента неправильного классифицирования данных систем мгновенного обмена сообщениями необходимо дополнительно разработать алгоритм автоматизации выбора порога классификации контента.
Список литературы:
- Система мгновенного обмена сообщениями [Электронный ресурс] // TADVISER центр выбора технологий и поставщиков: [сайт]. [2010]. URL: http://www.tadviser.ru/index.php/Статья:Система_мгновенного_обмена_сообщениями (дата обращения 20.10.2011).
- ICQ: растут и популярность, и угрозы [Электронный ресурс] // CNews. Интернет — издание о высоких технологиях: [сайт]. [2005]. URL: http://www.cnews.ru/reviews/free/security2005/articles/im.shtml?1 (дата обращения 20.10.2011).
- Воронцов К.В. Лекции по статическим (байесовским) алгоритмам классификации [Электронный ресурс] [2008] URL: http://www.ccas.ru/voron/download/Bayes.pdf (дата обращения 22.10.2011).
- Применяемость Байесовского классификатора для задачи определения спама [Электронный ресурс] // Securelist: [сайт]. [2005]. URL: http://www.securelist.com/ru/analysis/19230/Primenimost_Bayesovskogo_klassifikatora_dlya_zadachi_opredeleniya_spama (дата обращения 22.10.2011).
- Байесовская фильтрация спама [Электронный ресурс] // Википедия. Свободная энциклопедия: [сайт]. [2010]. URL: http://ru.wikipedia.org/w/index.php?title=Байесовская_фильтрация_спама&stable=0&redirect=no (дата обращения 22.10.2011).
- Нестеренко А.А. Элементарный лемматизатор [Электронный ресурс] // Международная конференция по компьютерной лингвистике: [сайт]. [2003]. URL: http://www.dialog-21.ru/Archive/2003/Nesterenko.htm (дата обращения 01.11.2011).
- Программы анализа и лингвистической обработки текстов [Электронный ресурс] // Русская виртуальная библиотека: [сайт]. [1999]. URL: http://rvb.ru/soft/catalogue/c01.html (дата обращения 03.11.2011).
- Программы лингвистического анализа и обработки текста [Электронный ресурс] // Семантическая поисковая система AskNet: [сайт]. [2007]. URL: http://asknet.ru/Analytics/programms.htm#Лингвистические технологии и системы (дата обращения 03.11.2011).
- Хеирхабаров Т.С. О применении синтаксического анализатора «COGNITIVE DWARF» в задаче фильтрации незапрашиваемой электронной корреспонденции. Материалы XV Международной научной конференции “Решетневские чтения”. — Красноярск: СибГАУ, 2011 г. — С.666‑667.
дипломов