
Статья опубликована в рамках: XXXVII Международной научно-практической конференции «Технические науки - от теории к практике» (Россия, г. Новосибирск, 27 августа 2014 г.)
Наука: Технические науки
Секция: Информатика, вычислительная техника и управление
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
АВТОМАТИЧЕСКАЯ ОЦЕНКА СМЫСЛОВОГО ПОДОБИЯ ТЕКСТОВ
Симанков Владимир Сергеевич
д-р техн. наук, профессор, Кубанский государственный технологический университет, профессор кафедры Компьютерных технологий и информационной безопасности, РФ, г. Краснодар
E-mail : vs@simankov.ru
Толкачев Демид Максимович
аспирант кафедры Компьютерных технологий и информационной безопасности, Кубанский государственный технологический университет, РФ, г. Краснодар
E-mail:
AUTOMATIC EVALUATION SEMANTIC SIMILARITY OF TEXTS
Vladimir Simankov
doctor of Technical Sciences, Professor, Kuban State Technological University, Professor of Computer Technology and Information Security department, Russia, Krasnodar
Demid Tolkachev
postgraduate student of Computer Technology and Information Security department, Kuban State Technological University, Russia, Krasnodar
АННОТАЦИЯ
В статье доработана и модифицирована методика автоматической оценки подобия тематического содержания текстов с учётом необходимости выявления смысловых противоречий.
ABSTRACT
In this paper we redesigned and modified the method of automatic evaluation of similarity of thematic text content, taking into account the need to identify the semantic differences.
Ключевые слова: текст; смысловое подобие; синоним; индикатор; вес.
Keywords: text; semantic similarity; synonym; indicator; weight.
Смысловое подобие двух текстов можно определить как сходность содержащейся в них информации. На основе признаков смыслового сходства [3], выделим критерии смыслового подобия текстов:
· степень пересечения понятийного состава (K1);
· совпадение элементов текста, на которые падает логическое ударение и которые имеют более высокое значение (K2);
· противоположность заложенных в текстах идей (K3).
Оценка смыслового подобия имеет широкое практическое применение. Рассмотрим её в контексте проблемно-ориентированного автореферирования (ПОА) [4]. Поскольку при поиске данных и знаний ПОА осуществляется по нескольким источникам, важно определить степень подобия полученных авторефератов и отдельных положений в них. Это позволит получить общий автореферат, не содержащий дублирующих друг друга фраз.
Методы определения нечётких дубликатов, рассмотренные в [2], не подходят для выявления общего в сгенерированных авторефератах, поскольку достаточно чувствительны к формальным изменениям текста, таким как перестановка слов, не затрагивающим его смысл. Более эффективным методом решения обозначенной задачи следует считать автоматическую оценку подобия текстов, предложенную в [1]. Однако она учитывает только критерии К1 и К2, не касаясь проблемы выявления противоречий. ПОА же предполагает определение двух фраз как дублирующих друг друга, если они подобны по смыслу, т. е. соответствуют друг другу по всем трём критериям. Кроме того, в [1] не определяются отдельные общие положения. Доработаем и модифицируем данную методику с целью автоматического выявления противоречий и определения общих и различных положений в наборе авторефератов.
Из текста автореферата удаляются знаки препинания, спецсимволы и незначащие слова — предлоги, союзы, частицы и междометия, кроме отрицательной частицы «не».
Далее при помощи морфологического анализа или с помощью стеммера Портера выделяются основы слов bw. По словарю синонимов/гипонимов каждая основа приводится к базовому варианту b, если она отлична от него. В обозначенном словаре также будут присутствовать устойчивые словосочетания, поэтому необходимо реализовать механизм их выявления в тексте. Базовый вариант определяется как первый член группы синонимов/гипонимов, для повышения быстродействия он должен состоять из одного слова. При этом у частиц «не» выделение основы не проводится, вместо этого они удаляются, а следующие за ними слова получают значение коэффициента koef = –1, тогда как его начальное значение для всех слов koef = 1.
Следует заметить, что в группы словаря синонимов/гипонимов нужно добавлять только наиболее близкие по смыслу слова.
В [1] каждое понятие получает вес, что служит для учёта критерия K2:
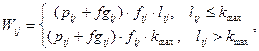 (1)
(1)
где: pij — коэффициент, увеличивающий степень значимости наименования понятия в зависимости от его принадлежности к фамильно-именной группе, географическим названиям и т. д.;
lij — количество слов в словосочетании, которым выражается j-ое понятие в i-ом тексте;
fij — частота появления j-ого понятия в i-ом тексте;
fgij — нормированная глобальная частота j-ого понятия в i-ом тексте;
kmax — коэффициент, установленный опытным путем, соответствующий максимальной длине словосочетания, после которой она не должна влиять на итоговый вес наименования понятия.
Поскольку при ПОА включение предложений в автореферат зависит, в первую очередь, от наличия в них определённых индикаторов, то разумно учитывать эти индикаторы и при сравнении двух авторефератов и выявлении общего. Частота же появления слова, безусловно, влияет на степень похожести текстов, но включение её в формулу расчёта веса представляется излишним, поскольку она учитывается далее при вычислении коэффициента подобия. Что касается длины понятия в словах, то этого параметра можно полностью избежать, в качестве базовой основы устойчивых словосочетаний используя синонимы, состоящие из одного слова, а если таковые отсутствуют — не распознавая данное устойчивое словосочетание. Это немного сократит размер словаря и повысит быстродействие при сходной точности работы.
Учитывая вышеизложенное, каждая основа bi получает вес wi, который зависит от присутствия bwi в словарях индикаторов и вычисляется по формуле:
![]() (2)
(2)
где: wQ — вес множества основ слов вопроса без ненужных QUES;
Qi — определяет, входит ли bwi в QUES, и принимает значение 1, если входит, иначе — 0;
wA — вес универсального словаря «действий» ACT;
Ai — определяет, входит ли bwi в ACT, и принимает значение веса индикатора bwi в ACT, если входит, иначе — 0;
wAS — вес множества ассоциированных со словами вопроса основ слов ASSOC;
ASi — определяет, входит ли bwi в ASSOC, и принимает значение 1, если входит, иначе — 0;
wT — вес набора словарных основ из тематического словаря TOPIC;
Ti — определяет, входит ли bwi в TOPIC, и принимает значение веса индикатора bwi в TOPIC, если входит, иначе — 0.
После вычисления весов для автореферата из множества базовых основ B составляется множество уникальных базовых основ UB:
![]() . (3)
. (3)
При этом вес ub вычисляется как среднее арифметическое весов b, которые объединил ub:
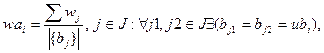 (4)
(4)
где: wai — вес ubi.
В [1] коэффициент подобия текстов вычисляется так:
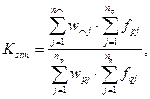 (5)
(5)
где: w∩j — j-ая компонента вектора весовых коэффициентов наименований понятий, содержащихся в обоих текстах, причем веса берутся из формализованного смыслового описания q-ого текста;
wpj — j-ая компонента вектора весовых коэффициентов наименований понятий, содержащихся в p-ом тексте;
fpj и fqj — j-ые компоненты вектора локальных частот наименований понятий, содержащихся в p-ом и q-ом текстах соответственно;
n∩ — размерность вектора наименований понятий, содержащихся в обоих текстах;
np и nq — размерности вектора наименований понятий, содержащихся в p-ом и q-ом текстах соответственно.
Формула (5) служит только для ответа на вопрос о тематическом подобии двух текстов, т. е. о том, излагаются ли в текстах мысли и сведения об одних и тех же вещах. Она учитывает критерии K1 и K2. Введём в расчёт коэффициента смыслового подобия все критерии поэтапно:
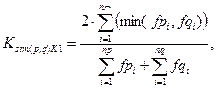 (6)
(6)
где: Ksim(p,q)K1 — коэффициент подобия авторефератов p и q с учётом только критерия K1;
n∩ — количество общих уникальных базовых основ слов ub у авторефератов p и q;
min(fpi, fqi) — функция определения минимального значения из количества bj = ubi в автореферате p и количества bj = ubi в автореферате q соответственно;
np, nq — количество ub у авторефератов p и q соответственно.
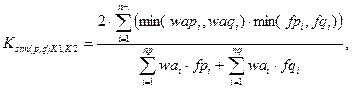 (7)
(7)
где: Ksim(p,q)K1,K2 — коэффициент подобия авторефератов p и q с учётом критериев K1 и K2;
min(wapi, waqi) — функция определения минимального значения из веса ubi в автореферате p и веса ubi в автореферате q соответственно.
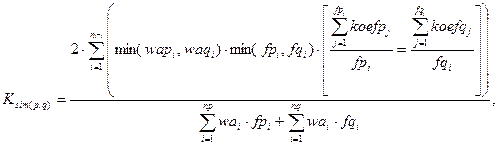 (8)
(8)
где: Ksim(p,q) — коэффициент подобия авторефератов p и q с учётом критериев K1, K2 и K3;
koefpj, koefqj — значения коэффициентов koef для bj авторефератов p и q соответственно.
В формуле (8) учитывается положительный и отрицательный характер высказывания, и полученный с помощью неё коэффициент подобия будет стремиться к единице лишь при пересечении понятийного состава, совпадении важных элементов текста и отсутствии противоположности заложенных в текстах идей одновременно.
Для определения общих и различных положений авторефераты разбиваются на абзацы P в соответствии с таким разбиением исходного текста. Допустимо осуществлять разбиение на отдельные предложения. Коэффициент подобия абзацев с учётом только критерия K1 будет вычисляться по аналогии с (6), учёт оставшихся двух критериев требует некоторых изменений расчёта, поскольку нельзя использовать веса уникальных базовых основ wa, а учёт противоречий должен быть более жёстким, так как предполагается, что в предложении или абзаце освещается какая-либо одна мысль:
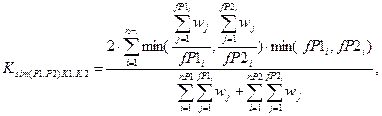 (9)
(9)
где: где Ksim(P1,P2)K1,K2 — коэффициент подобия абзацев P1 и P2 с учётом критериев K1 и K2; все прочие обозначения аналогичны соответствующим в (8).
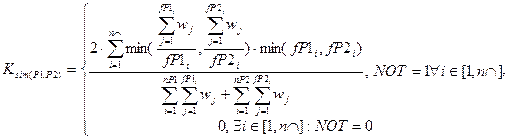 (10)
(10)
где: Ksim(P1,P2) — коэффициент подобия абзацев P1 и P2 с учётом критериев K1, K2 и K3;
NOT — логическая функция (11).
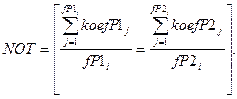 (11)
(11)
Если Ksim(P1,P2) выше некоторого установленного на основе экспериментальных данных порогового значения, то считается, что в абзацах или предложениях говорится об одном и том же, и их можно не дублировать. Таким образом, перебирая различные пары абзацев и оставляя только один из имеющих высокое значение Ksim(P1,P2), можно получить обобщённый автореферат по нескольким источникам. Он также может быть подвергнут процедуре автореферирования, если источников достаточно много.
Приведём пример для демонстрации различия понятий тематического и смыслового подобия. Рассмотрим две фразы:
·Человек однозначно произошёл от обезьяны, это можно считать научным фактом.
·Человек однозначно не произошёл от обезьяны, это можно считать научным фактом.
Тематическое подобие этих фраз, вычисленное с помощью любой методики, будет очень высоким и в большинстве случаев составит от 90 % до 100 %, поскольку в них говорится об одном и том же, их можно считать ответами на один вопрос. Однако отвечают они на этот вопрос диаметрально противоположно, т. е. содержат явное смысловое противоречие. Предложенная методика выявит это противоречие и определит их коэффициент смыслового подобия равным 0 %. Таким образом, рассмотренные фразы не будут признаны дублирующими друг друга по смыслу и смогут фигурировать в качестве альтернативных ответов на спорный вопрос.
В результате проведённого исследования можно сделать следующие выводы:
·С учётом необходимости выявления противоречий и определения сходства отдельных предложений и абзацев при проблемно-ориентированном автореферировании доработана и модифицирована методика автоматической оценки подобия тематического содержания текстов.
·Предложенная методика обладает практической эффективностью и определяет не только тематическое подобие текстов, но и выявляет в них смысловые противоречия в связи с учётом положительного или отрицательного характера высказываний, что позволяет получать ответы и информацию при проблемно-ориентированном автореферировании без дублирования.
Список литературы:
1.Захаров В.Н., Хорошилов А.А. Автоматическая оценка подобия тематического содержания текстов на основе сравнения их формализованных смысловых описаний // Труды XIV-ой Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции». RCDL’2012, Переславль-Залесский, Россия, 15—18 октября 2012 г.
2.Зеленков Ю.Г., Сегалович И.В. Сравнительный анализ методов определения нечетких дубликатов для Web-документов // Труды 9ой Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции». RCDL’2007, Переславль, Россия, — 2007. — Том 1, — С. 166—174.
3.Новичихина М.Е.. О некоторых трудных случаях лингвистической экспертизы товарных знаков [Электронный ресурс] — Режим доступа. — URL: http://siberia-expert.com/publ/4-1-0-303 (дата обращения 19.08.2014).
4.Симанков В.С., Толкачев Д.М. Проблемно-ориентированное автореферирование как инструмент поиска данных и знаний. Наука вчера, сегодня, завтра / Сб. ст. по материалам XIV междунар. науч.-практ. конф. № 7 (14). Новосибирск: Изд. «СибАК», 2014. — с. 31—35.
дипломов