
Статья опубликована в рамках: XVIII Международной научно-практической конференции «Технические науки - от теории к практике» (Россия, г. Новосибирск, 20 февраля 2013 г.)
Наука: Технические науки
Секция: Информатика, вычислительная техника и управление
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

ВЕРОЯТНОСТНАЯ МОДЕЛЬ РЕКОМЕНДАЦИИ КАНДИДАТОВ ДЛЯ СИСТЕМЫ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЙ В ПРОЦЕССЕ КОМАНДООБРАЗОВАНИЯ
Бейльханов Дамир Кайржанович
аспирант АГТУ, г. Астрахань
Email: mcproxa@yandex.ru
Квятковская Ирина Юрьевна
д-р техн. наук, профессор АГТУ, г. Астрахань
Email: i.kvyatkovskaya@astu.org
PROBABILISTIC MODEL RECOMMENDATION OF CANDIDATES FOR DECISION SUPPORT SYSTEM IN THE PROCESS OF TEAMBUILDING
Beylkhanov Damir Kayrzhanovich
Postgraduate of ASTU, Astrakhan
Kvyatkovskaya Irina Yurievna
Doctor of Technical Sciences, Professor of ASTU, Astrakhan
АННОТАЦИЯ
В данной статье рассматривается вероятностная модель рекомендаций, как отдельный модуль в системе поддержки принятия решений при отборе кандидатов для того, чтобы оценить скрытые аспекты модели предпочтений к работе, навыки и умения. Совместно с этим подходом формируется команда участников с аналогичными структурами в предпочтениях, основанные на скрытых аспектах, полученных из номинального профиля работы. Учитывая эти требования, на выходе получаем вычислительную модель надежности, позволяющая охватить как индивидуальные и другие навыки, выступающие в качестве входных параметров для системы поддержки принятий решений, обрабатывающая полученные данные.
ABSTRACT
This article discusses the probability model recommendations as a separate module in the decision support system for the selection of candidates to evaluate the hidden aspects of the model of preferences for work, skills and abilities. In conjunction with this approach, the participants formed a team with similar structures in preference based on hidden aspects derived from the nominal job profile. Considering these requirements, as a result is a reliable computational model extends the individual and other skills that serve as input criteria for a decision support system that processes the data.
Ключевые слова: командообразование, модель надежности, система поддержки принятия решений, скрытые навыки, отношение доверия, вычисление надежности на основе рекомендаций, вычисление надежности на основе доверия.
Key words: teambuilding, reliability model, decision support system, latent skills, trust relation, the calculation of reliability based on the recommendations, the calculation of reliability based on trust.
На сегодняшний день сложность командообразования объясняет отсутствие коммерческих программных продуктов, так как большинство доступных систем основаны на применении обычного поиска ключевых слов и методов фильтрации посредством стандартных запросов к базе данных. Более инновационный подход был представлен Lang A. и Pigneur Y. в 1999 году, кто основал внутренний рынок рекрутмента для оценки компетенций кандидатов, представленный в виде деревьев способностей и навыков [2].
Однако, фактическое соответствие кандидатов, по-прежнему базируется на формировании стандартных запросов к базе данных, чтобы найти кандидатов, которые удовлетворяют критериям поиска. В данной работе рассматривается подход по применению вероятностной модели, которая предоставляет автоматизированный подход по рекомендации кандидатов в системе поддержки принятия решений (СППР).
Автоматизированные системы рекомендаций были изначально разработаны с целью поиска информации. Большинство проблем связано с информационной перегрузкой, помогая клиентам с поиском товаров или услуг, которые удовлетворяют их предпочтениям. Для таких случаев обычно использовались методы на основе поиска по контенту и/или общие методы фильтрации [4].
Такая система рекомендаций изначально применялась для продвижения товаров (такие как фильмы или книги) пользователям. Их вероятностная гибридная модель рекомендаций адаптирована под вероятностный скрытый семантический анализ, описанный Хофманном [5]. Данная модель интерпретирует предпочтения пользователей как выпуклая комбинация, лежащая в основе скрытых навыков.
На рисунке 1 показано графическое представление модели скрытых навыков, используемая для сравнения участников. Параметры модели оцениваются, используя алгоритм максимально-ожидаемого результата [3], где x представляет рекрутера с предлагаемой вакансией, и a представляющий навыки кандидата y, состоящий из четырёх частей, такие как например, a = («математические навыки», «степень диплома», «1.0», «Московский государственный университет»). Скрытые навыки рассматриваются в модели используя скрытые переменные, в виде следующего выражения: ![]() .
.
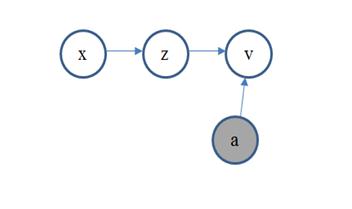
Рисунок 1. Модель рекомендаций кандидата
Модель окончательных результатов в рейтинговой матрице ![]() включает вероятность того, что рекрутер X оценил кандидата Y с оценкой V [8]. Последний параметр может любым значением или в общем случае определен как:
включает вероятность того, что рекрутер X оценил кандидата Y с оценкой V [8]. Последний параметр может любым значением или в общем случае определен как: ![]() , где 0 — не подходит, 1 — подходит.
, где 0 — не подходит, 1 — подходит.
Этот вероятностный подход автоматически рекомендует кандидатов, которые лучше всего подходят на вакансию на основе прошлых результатов рейтинга и с учетом их основных навыков [7]. Однако, модель имеет некоторые недостатки, так как она ориентирована только на индивидуальные навыки кандидатов, которые непосредственно связаны с ними и таким образом, позволяет только прогнозировать соответствие кандидата должности. Данный метод не учитывает дополнительную информацию для оценки навыка кандидата работать в команде.
Поэтому необходимо расширить данную модель, включив в нее подход, основанный на рекомендациях для оценки такого навыка, как умение работать в команде. Данный подход позволит повысить качество прогнозирования при подборе кандидатов для формирования эффективной команды.
Будем использовать более адаптированную модель вероятностного подхода для прогнозирования соответствия кандидата, таким же образом, как она используется в рекомендации кандидата для того, чтобы определить предпочтения к работе, на основе прошлых рабочих мест. Совместно с этим подходом образуются команда участников с аналогичными структурами в предпочтениях, основанные на скрытых навыках, полученных из номинального профиля работы. Таким образом, важно знать, что один пользователь может состоять в нескольких группах, в отличии от методов кластеризации [6]. Сходство между двумя пользователями может быть рассчитано следующим образом:
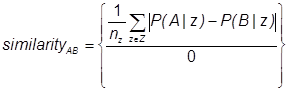 (1)
(1)
В первом случае, выражение справедливо при условии: ![]() и в противном случае, оно равно 0.
и в противном случае, оно равно 0.
![]() — схожесть к скрытому навыку z,
— схожесть к скрытому навыку z,
![]() — число переменных z,
— число переменных z,
![]() — количество оцененных профилей рабочих мест между кандидатами A и B.
— количество оцененных профилей рабочих мест между кандидатами A и B.
Попросту говоря, осуществляется вычисление разности вероятности того, что два кандидата относятся к сегменту, который включает в себя скрытый навык z. Подытожим различия всех скрытых аспектов и разделим на количество сегментов. В случае, если у нас нет совместно-оцененного профиля работы между двумя кандидатами, то нет возможности рассчитать значение сходства, поскольку алгоритм максимально-ожидаемого результата не будет генерировать результаты, потому что он выполняется со случайными значениями, которые не могут быть правильно заданы, если схожие профили работы не найдены [6]. Предположим, что положительная корреляция между сходством пользователей и доверии присутствует, то мы получаем следующее:
![]() .
.
По мере увеличения, число совместных по рейтингу профилей работы является индикатором точности значения прогнозируемого доверия, и мы можем использовать его в качестве весового коэффициента для расчета доверия на основе сходства. В качестве примера, рассмотрим сценарий с тремя отдельными профилями A, B и C, которые не имеют явных рейтингов доверия друг к другу. Тем не менее, А и В, а также B и C имеют общую структуру предпочтения в отношении их совместного рейтинга в профиле работы. Эти сходства предпочтений структуры используются для расчета сходства значения на основе доверия. Это позволяет нам оценить до сих пор неизвестные отношения доверия между кандидатами А и С следующим образом [8]:
![]() (2)
(2)
Другими словами, вычисленные значения предполагаемого доверия ![]() ,
,![]() ,
,![]() суммируются, и сравниваются с количеством оцененных профилей работы каждой прямой связи. Вычисленное значение лежит между значениями двух прямых отношений доверия. Если сумма совместного рейтинга профилей работы меняется, значение доверия соответствующей связи изменяется таким же образом [1].
суммируются, и сравниваются с количеством оцененных профилей работы каждой прямой связи. Вычисленное значение лежит между значениями двух прямых отношений доверия. Если сумма совместного рейтинга профилей работы меняется, значение доверия соответствующей связи изменяется таким же образом [1].
Подход на основе сходства позволяет вычислить сценарий, где непосредственно сочетаются индивидуальные и реляционные характеристики. На основе имеющихся профилей кандидатов A, B, C и D вместе с действующим доверительным отношением ![]() , мы можем вычислить сходства между парами d(x,y). С учетом полученных данных, возможно, прогнозировать рейтинг доверия для неизвестной связи
, мы можем вычислить сходства между парами d(x,y). С учетом полученных данных, возможно, прогнозировать рейтинг доверия для неизвестной связи ![]() [1].
[1].
Используя данный подход предоставляется возможность интеграции данной модели в систему поддержки принятия решений для подбора кандидатов, где будет происходить обработка скрытых аспектов, предпочтений к работе, навыков и умений кандидатов. Совместно с этим подходом формируется команда участников с аналогичными структурами в предпочтениях, основанные на скрытых аспектах, полученных из номинального профиля работы. Прототип приложения будет выполнен в виде отдельного приложения, построенного на основе реляционной модели использующей профили кандидатов, а также последние рейтинги и результаты надежности. На следующем этапе, необходимо проверить реализацию и вероятностную модель использующейся в этом приложении, и провести предварительное тестирование обобщенных данных полученных после обработки.
Список литературы:
1.Бейльханов Д.К., Квятковская И.Ю. «Использование подхода основанного на рекомендациях в процессе командообразования». // Всероссийская научная конференция молодых ученых, аспирантов и студентов. «Проблемы автоматизации. Региональное управление. Связь и автоматика» (ПАРУСА-2012). Сборник трудов, Южный федеральный университет, Геленджик, 2012, С. 16—20.
2.Abdul-Rahman A., Hailes S. «Supporting trust in virtual communities». Proceedings of the 33rd Hawaii International Conference on System Sciences, Maui, Hawaii, USA, January 4—7, 2000. — 23 pages.
3.Dempster A.P., Laird N.M. and Rubin D.B. «Maximum likelihood from incomplete data via the EM algorithm», J. Royal Statist. Soc., B 39, 1977, pp. 1—38.
4.Guha R., Kumar R., Raghavan P. and Tomkins A. «Propagation of Trust and Distrust». Proceedings of the World Wide Web, New York, USA, May 17—22, 2004. — pp. 403—412.
5.Hofmann T. «Probabilistic latent semantic analysis», Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence (UAI), July 30 August 1, Stockholm, Sweden, 1999, pp. 289—296.
6.Lang A. and Pigneur Y. «Digital trade of human competencies», Proceedings of the 32nd Annual Hawaii International Conference on System Sciences, Hawaii, USA, 1999, pp. 165—173.
7.Papagelis M., Plexousakis D. and Kutsuras T. «Alleviating the Sparsity Problem of Collaborative Filtering Using Trust Inferences», to appear in the 3rd international conference on trust management, iTrust, 2005.
8.Resnick P. and Varian H.R. «Recommender systems», Communications of the ACM, 40 (3), 1997, pp. 56—58.
дипломов