
Статья опубликована в рамках: XLI Международной научно-практической конференции «Технические науки - от теории к практике» (Россия, г. Новосибирск, 24 декабря 2014 г.)
Наука: Технические науки
Секция: Информатика, вычислительная техника и управление
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
ПОСТРОЕНИЕ МАТЕМАТИЧЕСКОЙ МОДЕЛИ СЕЛЕКТОРА СИНГУЛЯРНОГО ЭСТИМАТОРА МГНОВЕННОЙ ЧАСТОТЫ ОСНОВНОГО ТОНА РЕЧИ
Вольф Данияр Александрович
аспирант, Томского государственного университета систем управления и радиоэлектроники, РФ, г. Томск
A BUILDING MATHEMATICAL MODELS OF SELECTOR OF SINGULAR ESTIMATORS PITCH TRACKER
Daniyar Volf
graduate student, Tomsk State University of Control System and Radioelectronics, Russia, Tomsk
АННОТАЦИЯ
Исследуется новый метод оценивания мгновенной частоты основного тона речи. Получена математическая модель процесса, протекающего в селекторе сингулярного эстиматора мгновенной частоты основного тона речи (singular estimation pitch tracking — SEPT).
ABSTRACT
We study a new method for estimating the instantaneous frequency of the fundamental tone of natural speech. Obtained by mathematical model of the processes, which flows in singular estimator pitch tracking (SEPT).
Ключевые слова: речь; фонема; модель; сингулярный спектральный анализ речи; сингулярное оценивание частоты основного тона.
Keywords: speech; phoneme; model; singular spectrum analysis of speech; singular estimation pitch tracking.
Введение . Современные информационные технологии находят все более широкое применение в вычислительных и телекоммуникационных системах. Актуальной становится задача разработки и внедрения новых методов средств анализа информации для обеспечения потребителя максимальными данными об исследуемых объектах.
Предметом данного моделирования является процесс оценивания одного из основных параметров устной речи — частоты колебаний голосовых связок при произнесении вокализованной речи, называемой основным тоном — F0 (величина обратная периоду T0 = 1/F0).
В настоящее время популярными алгоритмами оценивания частоты основного тона речевого сигнала являются RAPR, YIN и SWIPE’ Популярность перечисленных алгоритмов обусловлена хорошей функциональностью, низким процентом грубых ошибок и наличием свободно распространяемых версий их реализаций [1, с. 49].
Главным недостатком подобных алгоритмов является зависимость от точности нахождения пиков. Наличие пиков и их амплитуда зависят от длины и вида окна анализа, а также от класса звука, что довольно часто приводит к ошибкам. Более того, точность зависит от значения частоты основного тона и от частоты дискретизации [9, с. 16].
Еще одно ограничение обусловлено периодической (стационарной) моделью сигнала, лежащей в их основе, которая подразумевает точное повторение периода основного тона и не допускает его изменения на протяжении анализируемого фрейма. Например, при появлении модуляций — изменений частоты основного тона, точность оценок также существенно снижается.
В процессах исследования речевых сигналов, обычно используется математические аппараты спектрального анализа Фурье или вейвлет-анализ (wavelet-analysis). Однако в настоящей работе применен аппарат сингулярного спектрального анализа (ССА «Гусеница»), разработанного и обоснованного в конце XX века сотрудниками Санкт-Петербургского государственного университета [7, с. 5], [8, с. 1]. Также в современной зарубежной литературе описан достаточно широкий класс методов, алгоритмически и идейно близких к методу «Гусеница», в основном метод известен как Singular Spectrum Analysis (SSA).
Метод основан на анализе главных компонент и позволяет исследовать стационарные и не стационарные временные ряды. Связь между классическими методами анализа стационарных временных рядов и методом главных компонент рассматривается в работах Бриллинджера [2, c. 1].
Например, в работе Bagshaw [10, с. 1] утверждается, что, методы, работающие во временной области, обладают наименьшей по сравнению с другими методами (частотными), ошибкой принятия решения о присутствии голоса в речи (voicing decision error rate) — не более 17 %. Кроме того, в работе [11, с. 399] показано, что такие методы являются наиболее робастными в отношении принятия решения о вокализованности или невокализованности сегмента речи в условиях шума (voiced-unvoiced decision), искажений и побочных помех в сигнале.
Задача . Дан временной ряд S длинны N. Выделить периодическую составляющую T0N (base tone track), где fmin ≤F0≤ fmax при условии, что частота обертоновых составляющих речи кратна частоте основного тона. Вычислить среднюю амплитуду T0N.
Технические требования к модели. Исходя из поставленной задачи сформулируем технические требования к модели (рис. 2):
1. Входные данные: SN — фонемный ряд гласных звуков речи длины N отсчетов с выборкой Fd кГц;
2. Выходные данные: F0 — частота основного тона речи, содержащаяся во временном кадре t мс; Amp — средняя амплитуда гармоники, соответствующая частоте основного тона речи; T0N — временной ряд, соответствующий квазигармонической составляющей (субфонеме) с частотой основного тона речи.

Рисунок 1. Требования к модели процесса оценивания мгновенной ЧОТ речи
Построение концептуальной модели. Для последующего построения концептуальной модели процесса сингулярного оценивания мгновенной частоты основного тона речи следует сначала понять физический процесс речеобразования и рассмотреть модель речевого сигнала для вокализированного сегмента речи. Однако несмотря на то, что речеобразующий механизм представляет собой относительно труднодоступную систему, даже на современном этапе представляется весьма сложным получить точные данные всех параметров речевого тракта и подробное описание его динамики известно, что человеческая речь по своей структуре состоит из некоторого количества системообразующих факторов, связанных между собой либо структурно, либо по механизму взаимодействия, которые демонстрируются на примере акустических свойств речи. Так как звуки речи генерируются артикуляционным аппаратом человека, то понимание акустики речеобразования позволяет правильно интерпретировать физические данные.
Одним из источников образования звуков является голосовой источник, который возникает при колебании голосовых связок. Он участвует в образовании нескольких групп звуков, и по степени участия голосового источника звуки делятся на гласные и согласные. Для вокализированного сегмента речи экспериментально было установлено, что на «фонетический смысл» гласных звуков существенно влияют амплитуды на частотах основного тона и обертоновых составляющих речевого сигнала.
Рассмотрим модель вокализованного сегмента речевого сигнала применительно к задачам анализа и синтеза речи: Входной сигнал x(t) поступает от голосовых связок (природный квазигармонический генератор — генеративная система), проходит через N-е количество параллельно соединенных резонаторов (характеризующих форму речевого тракта), в следствие чего, на выходе формируется определенный произносимый вокализованный речевой сегмент y(t). Таким образом, математическую модель вокализованного речевого сегмента можно описать в виде суммы некоторого набора амплитудных, фазовых и частотных параметров, формируемых в результате прохождения полигармонического колебания через резонансную систему [9, с. 14]:
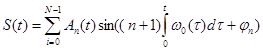 , (1)
, (1)
где: n=0, 1, 2… — номер гармоники основного тона;
An — амплитуды гармоник;
w0 — частота основного тона, рад/сек;
jn — начальная фаза гармоник;
S (t) — конечный продукт генеративной и резонансной системы.
Очевидно, что, имея только выходной конечный продукт S(t), появляется необходимость (интерес) решения обратной задачи (1) для выделения генеративной и резонансной составляющей. Научным интересом решения такой задачи может послужить построение импульсных характеристик резонансной системы для распознавания или дальнейшего синтезирования речи диктора и т. д.
Таким образом для определения частоты основного тона речи формулируются две задачи:
1. Разложение исходного речевого сигнала в спектр квазигармонических компонент (задача 1);
2. Выбор квазигармонической составляющей соответствующей частоте основного тона речи (задача 2).
Сформулируем некоторое эвристическое описание модели сингулярного оценивания частоты основного тона:
Пусть SN — одномерный массив данных равностоящих значений (набор из квантов по уровню), полученных в результате дискретизации непрерывного множества S(t), поступает на вход системы осуществляющей расщепление в элементарный спектр временных рядов, генерируемых каждым резонатором речевого тракта. На выходе такой системы соответственно многомерный массив данных равностоящих значений TL,N — временной пучок (субфонемный спектр). Такую задачу разложения формально запишем как функцию сингулярного спектрального анализа [3, с. 114], [4, с. 69]:
![]() ,
, ![]() ,
, ![]() . (2)
. (2)
Проводя аналогию с типовыми, уже ставившими классическими, оценщиками частоты основного тона речи, процесс (2) эквивалентен процессу генерации кандидатов искомого периода основного тона, однако в отличии от кросскорреляционных подходов в данном случае происходит генерация заранее известных функций (генератор сингулярных кандидатов частоты основного тона речи или генератора сингулярного спектра).
Далее временной пучок TL,N совместно с исходным сигналом SN поступают на вход системы осуществляющей выбор функции соответствующей действительному кандидату частоты основного тона речи. На выходе данной системы набор параметров, описывающих частоту основного тона речи в виде Amp — амплитуды сигнала, F0 — частотной характеристики и T0N — трека (track) самой функции с ЧОТ. Выбор квазигармонической составляющей соответствующей частоте основного тона речи формализуем некоторой функцией выбора:
![]() . (3)
. (3)
Аналогично процессу протекающего в модуле постобработки типовых оценщиков, в селекторе (3) происходит срабатывание решающего правила выбора наилучшего кандидата с последующим уточнением значения частоты основного тона речи.
Объединяя (2), (3) подходим к некоторому обобщенному концептуальному описанию модели сингулярного оценивания в следующей системе (рис. 2):
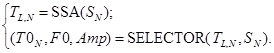 (4)
(4)
Если в системе (4) решение равенства (2) однозначно определяется решением задачи сингулярного спектрального разложения одномерного временного ряда в многомерный [5, с. 81], [6, с. 129], то равенство (3) требует некоторого детального рассмотрения.
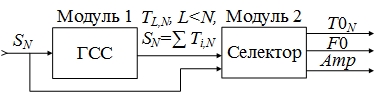
Рисунок 2. Обобщенная схема концептуальной модели SEPT : SN — входной сигнал; TL,N — временной спектр; ГСС — генератор сингулярного спектра; SN — входной сигнал; T0N — трек с ЧОТ; F0 — ЧОТ; Amp — амплитуда
Проведем следующие эвристические рассуждения, описывающие модель селектора (3): Поступая на вход селектора временной пучок TL,N сохраняется в некотором блоке управления матрицы временного спектра (УМВС).
Из условия первоначальной задачи известно, что частота обертоновых составляющих речи кратна частоте основного тона, а также известны границы ее существования, таким образом ставиться задача уменьшения плотности временного пучка L до величины K, обеспечивая сужение границ поиска f0ϵ[fmin, fmax]. Одним из вариантов решения данной задачи может выступать процесс измерения частотной характеристики элементов временного пучка TL,N с помощью быстрого преобразования Фурье в блоке измерения частоты временного спектра (ИЧВС):
![]() ,
, ![]() ,
, ![]() , (5)
, (5)
где fi — частотный ряд.
На выходе блока измерения частоты временного спектра (5) соответственно частотный ряд длины K, который поступает на вход блока выбора частоты основного тона (ВЧОТ). Теперь ставиться задача выбора частоты основного тона речи из полученного спектра. Пусть в качестве критерия выбора ЧОТ взята наименьшая кратная величина частоты
![]() , (6)
, (6)
тогда ряд T0 может быть вычислен как процедура математической свертки:
![]() , (7)
, (7)
где: Hk(f0) — динамическая конечно импульсная характеристика фильтра c частотой среза f0 +∆f;
S — исходный временной ряд.
По условию ряд T0N — квазигармоническая функция, соответствующая ЧОТ на заданном промежутке времени (определяется N и частотой дискретизации) с учётом модуляции, тогда можно говорить о вычислении средних величин F0 и Amp:
![]() ; (8)
; (8)
![]() , (9)
, (9)
где: m — число переходов через нуль;
f 0m — мгновенная частота тона;
Обобщая (5,7—9) и условие (6) получаем концептуальное описание модели селектора (3) в следующей системе (рис. 3):
 (10)
(10)
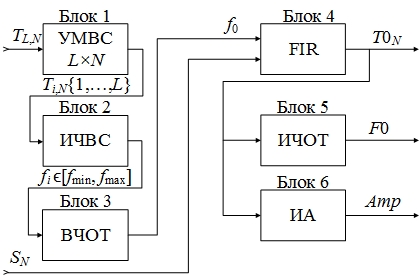
Рисунок 3. Схема модуля селектора SEPT : УМВС — блок управления матрицей временного спектра; ИЧВС — блок измерения частоты временного спектра; ВЧОТ — блок выбора ЧОТ; FIR — блок фильтрации; ИЧОТ — блок измерения ЧОТ; ИА — блок измерения амплитуды
Построение математической модели селектора. Согласно концептуальной модели проведем математическое моделирование процесса, протекающего в селекторе (3). Данную задачу сведем к решению известного класса математических задач в численном виде. Для этого осуществим математическую постановку задачи 2, а также проведем численное решение.
Математическая постановка задачи 2:
Из спектра временных рядов Tin [i=0,1,…,N-1; n=0,1,…,L-1] выбрать ряд удовлетворяющий следующим условиям:
Численное решение задачи 2:
Раскроем (5) следующим образом
![]()
![]() ,
, 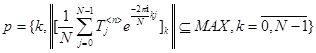
![]() , (11)
, (11)
где: ∆t — частота дискретизации;
p — индекс с максимальной амплитудой в результате преобразования Фурье в n-й квазигармонике (компоненте).
Исходя из условия в (5) осуществим отбор кандидатов ЧОТ в заданном диапазоне (сужение границ поиска):
![]() ,
,
![]() ,
, ![]() . (12)
. (12)
В соответствии с условием (6) из диапазона (12) выберем кандидата f0 по следующему правилу:
![]() . (13)
. (13)
Введем вспомогательный ряд Hi, численно описывающий конечно-импульсную характеристику фильтра нижних частот (ФНЧ):
![]() ,
,
![]() ,
,
![]() ,
,
![]() , (14)
, (14)
где: fc — частота среза;
Wi — ряд численно описывающий окно Блэкмена.
Тогда искомый ряд T0N (7) определяется сверткой
![]() ,
, ![]() . (15)
. (15)
Усреднение (8) — это сумма m обратных величин равных периодам умещающихся в ряде T0N
![]() …
…
![]() ,
,
где km — номер индекса в точке максимума
![]() .
.
Перепишем (8) в сумму
![]() . (16)
. (16)
Решение для (8) найдем как усреднение максимумов (15) по заданным мгновенным частотам (амплитудам на заданных частотах) из (16)
![]() ,
, ![]() . (17)
. (17)
Объединим (11-17) в систему:
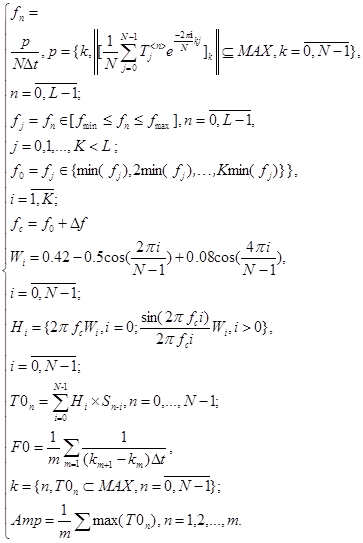 (18)
(18)
Система (18) описывает математическую модель процесса, протекающего в модуле селектора (3).
Вывод. Получена математическая модель процесса, протекающего в селекторе (3) сингулярного эстиматора мгновенной частоты основного тона речи. Рассматривая современные технологии оценивания ЧОТ, применение генератора сингулярного спектра задает новый класс методов оценивания. Оценка адекватности и достоверности полученной модели требует дополнительной работы.
Список литературы:
1.Азаров И.С., Вашкевич М.И., Петровский А.А. Алгоритм оценки мгновенной частоты основного тона речевого сигнала / Цифровая обработка сигналов, — № 4, — 2012. — С. 49—57.
2.Бриллинджер Д. Временные ряды. Обработка данных и теория. М: Мир, 1980. —536 с.
3.Вольф Д.А. Выделение частоты основного тона речи методом сингулярного спектрального анализа / Системы управления и информационные технологии, — № 2.1(56), — 2014. —С. 114—120.
4.Вольф Д.А. Автоматизация детектирования квазигармонических компонент, содержащих частоту основного тона речи в методе сингулярного спектрального анализа SSAPD / Системы управления и информационные технологии, — № 3(57), — 2014. — С. 69—75.
5.Вольф Д.А. Программная реализация подсистемы быстрого сингулярного спектрального анализа речи // Системы управления и информационные технологии, — № 4(54), — 2013. — С. 81—86.
6.Вольф Д.А. Спектральная теорема для решения частичной проблемы собственных чисел степенным методом в задачах сингулярного спектрального анализа речи / Системы управления и информационные технологии, — № 3.1(57), — 2014. — С. 129—135.
7.Голяндина Н.Э. Метод «Гусеница» — SSA: анализ временных рядов / Учебное пособие / Санкт-Петербург, 2004. — C. 5—6.
8.Данилов Д.Л., Жиглявский А.А. Главные компоненты временных рядов: метод «Гусеница» / Под ред. Д.Л. Данилова, А.А. Жиглявского / СПб: Пресском, 1997. — 308 с.
9.Конев А.А. Модель и алгоритмы анализа и сегментация речевого сигнала / Диссертация на соискание ученой степени кандидата технических наук по специальности 05.13.18 математическое моделирование, численные методы и комплексы программ / Федеральное агентство по образованию РФ. Томский государственный университет систем управления и радиоэлектроники: Томск, 2007. — 128 с.
10.Bagshaw P.C. Automatic prosodic analysis for computer aided pronunciation teaching / Univ. of Edinburgh, Edinburgh. PhDThesis 1994 / — [Электронный ресурс] — Режим доступа. — URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.55.3401 (дата обращения: 30.11.2014).
11.Rabiner L.R., Cheng M.J., Rosenberg A.E. A comparative study of several pitch detection algorithms / IEEE Trans. Acoust. Speech, — № 24, — 1976. — Р. 399—423.
дипломов