
Статья опубликована в рамках: LII Международной научно-практической конференции «Технические науки - от теории к практике» (Россия, г. Новосибирск, 18 ноября 2015 г.)
Наука: Технические науки
Секция: Информатика, вычислительная техника и управление
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
РАЗРАБОТКА РЕКОНФИГУРИРУЕМОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ ДЛЯ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛА
Мартенс-Атюшев Дмитрий Сергеевич
магистрант кафедры Вычислительных машин и систем
Пензенского государственного технологического университета,
РФ, г. Пенза
E-mail: novoselich93@mail.ru
Мартышкин Алексей Иванович
канд. техн. наук, доцент кафедры Вычислительных машин и систем
Пензенского государственного технологического университета,
РФ, г. Пенза
E-mail:
DEVELOPMENT OF RECONFIGURABLE COMPUTING SYSTEMS FOR DIGITAL SIGNAL PROCESSING
Dmitriy Martens-Atushev
master student Department of Computational Systems and Machines
of Penza State Technological University,
Russia, Penza
Alexey Martyshkin
candidate of Science, assistant professor Department of Computational Systems and Machines
of Penza State Technological University,
Russia, Penza
Работа выполнена при финансовой поддержке Всероссийского конкурса молодежных проектов (Росмолодежь) в рамках молодежного форума «Территория смыслов на Клязьме»
АННОТАЦИЯ
В статье повествуется высокопроизводительная реконфигурируемая вычислительная система (РВС). Выделяются и описываются два основных блока, входящих в состав РВС – диспетчер задач и аппаратный буфер памяти. Предлагается реализовать данное устройство на современной элементной базе – ПЛИС. В заключении приводятся выводы по работе.
ABSTRACT
The article tells of a high-performance reconfigurable computing system (RСS). Stand and describes the two main blocks that make up the RCS – Task Manager and buffer memory device. It is proposed to implement the device on modern element base – FPGA. Finally given the conclusions of the work.
Ключевые слова: многопроцессорная система; параллельные процессы; диспетчер задач; аппаратный буфер памяти; язык VHDL; аппаратная реализация; реконфигурируемая вычислительная система; высокопроизводительная система.
Keywords: multiprocessing, parallel processes; Task Manager; hardware buffer memory; language VHDL; a hardware implementation; reconfigurable computing system; high-performance system.
В последние годы благодаря развитию программируемых логических интегральных схем (ПЛИС) имеется возможность перехода от программной к аппаратной реализации алгоритмов операционных систем (ОС), которая способствует уменьшению времени выполнения алгоритма, тем самым повышая производительность вычислительных систем (ВС). Стоимость такой реализации так же значительно снижается благодаря росту развития современной элементной базы.
В данной статье рассмотрен ряд вопросов, посвященных диспетчеризации задач (ДЗ), при назначении их по центральным процессорам (ЦП), планирование процессов, а также проблему конфликтов на общей шине (ОШ) и потерю шинных циклов при обращении ЦП к памяти в многопроцессорных системах (МПС).
В МПС есть канал передачи, к которому подключены все ЦП – ОШ, в функции которой входит обмен данными между ЦП, оперативной памятью и внешними устройствами. В реальных МПС на занятие ОШ могут претендовать сразу несколько ЦП, однако в каждый момент времени сделать это может только одино из них. Чтобы исключить конфликты, ОШ должна предусматривать определенные механизмы арбитража запросов и правила предоставления одному из ЦП.
Для реализации аппаратного буферного устройства использована шина AMBA АНВ, спецификация которой [1], разработана как стандарт коммуникаций для высокопроизводительных систем-на-кристалле. АМВА — шина, пригодная для использования с процессорными ядрами разных архитектур. Она разработана с учетом возможностей коммуникаций внутри кристалла, с ориентацией на минимизацию аппаратных затрат на кристалле для организации взаимодействия и пересылки информации между объединяемыми модулями.
ОШ выступает посредником между ЦП и памятью. При непрерывном выполнении операции записи или чтения памяти ОШ монопольно владеет один из ЦП системы до тех пор, пока операция не завершится. Таким образом, ОШ и ЦП находятся в режиме ожидания до тех пор, пока память не произведет физическую процедуру чтения или записи. В результате теряются шинные циклы, которые могли быть использованы другими ЦП. Для уменьшения временных потерь и повышения пропускной способности ОШ нужно, чтобы она поддерживала режимы расщепления и буферизации.
Расщеплению подвергается операция чтения памяти, причем она делится на адресную операцию и операцию данных. При обращении к памяти ЦП выставляет на шину адрес, который сохраняется в буфере, после чего ОШ освобождается, а ЦП переходит в режим ожидания. Процедура физического чтения происходит в памяти самостоятельно под управлением буфера, который по окончании процедуры физического чтения должен сигнализировать запрашивающий ЦП о готовности данных. В ответ ЦП вновь запрашивает ОШ и читает слово данных из буфера [2].
Буферизации подвержены операции записи и заключаются в том, что ЦП выставляет на ОП адрес ячейки памяти и записываемые данные. Они сохраняются в регистрах контроллера памяти, после чего ЦП освобождает ОШ, поскольку обратная реакция памяти в этом случае отсутствует. Процедура записи в память происходит под управлением аппаратного буфера.
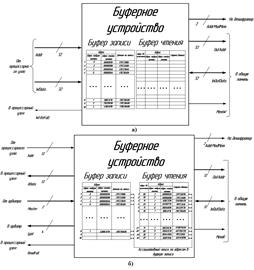
Рисунок 1. Схема аппаратного буфера: процесс записи (а), процесс чтения (б)
Из вышесказанного ясно, что блок памяти должен быть снабжен двумя буферами для хранения операций чтения и записи (рисунок 1). В свою очередь буфер чтения состоит из двух частей, первая содержит регистры для хранения адреса ячейки памяти, в которую производится обращение, вторая – регистры для хранения выбранных из памяти данных. Буфер записи тоже состоит из двух частей. В первой хранятся адреса ячейки памяти, в которую производится обращение, во второй хранятся записываемые данные.
Принцип действия аппаратного буфера заключается в следующем. Допустим, один или несколько ЦП одновременно сгенерировали операцию на запись. Для успешной реализации операции, необходимо получить доступ к ОШ, для чего ЦП посылают сигналы запроса в арбитр, он в свою очередь проверяет, свободна ли ОШ в данный момент, и выбирает по определенному правилу один из ЦП для осуществления операции. Если ОШ свободна, то ЦП занимает её. Далее происходит проверка на заполнение аппаратного буфера записи, в случае, если он полон, ЦП переводится в режим ожидания. Если имеется хотя бы один свободный регистр в аппаратном буфере записи, то ЦП помещает туда слово данных. Дальнейшая работа ЦП не зависит от результата записи, т. е. ему нет смысла дожидаться окончания записи, поэтому он освобождает ОШ.
В буфере записи могут скопиться запросы, и возможна ситуация, когда запрос на чтение будет ссылаться на данные, находящиеся в аппаратном буфере, а не в памяти, и их можно прочитать напрямую из буфера, а не из памяти, что существенно быстрее, чем обращение к модулям памяти. Для быстрой реализации этой функции адресный буфер записи выполняется в виде ассоциативной памяти [2].
Процедура чтения с расщеплением операций допускает совмещение по времени сразу нескольких операций, формируемых разными ЦП. В начале операции чтения запрашивающий ЦП занимает ОШ, выставляет на неё адрес и сигнал чтения, которые фиксируются в буфере чтения. Эта операция выполняется быстро, поскольку буферы реализуются на аппаратных регистрах. После этой процедуры ЦП отключается от ОШ. Далее аппаратный буфер самостоятельно осуществляет процесс физического чтения данных из модуля памяти и сохранения результата в одном из регистров буфера чтения. В подходящий момент времени, когда ОШ свободна, данные возвращаются ЦП.
При проектировании МПС возникает ситуация уменьшения временных потерь, проявляющихся, при планировании процессов [2]. Частью планировщика является функция диспетчеризации задач (ДЗ) при их назначении по ЦП. В настоящей статье ДЗ реализован аппаратно, что определенно снимает проблему временных потерь [2].
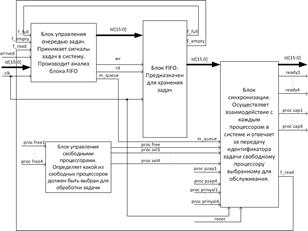
Рисунок 2. Схема диспетчера задач
На рисунке 2 представлены блоки:
Блок управления очередью задач – предназначен для приема идентификаторов задач в систему. Анализирует есть ли свободное место в очереди задач, и если есть, помещает идентификатор новой задачи в FIFO. Также осуществляет выборку идентификатора задачи из очереди для обслуживания в свободном ЦП.
Блок FIFO для хранения задач – предназначен для хранения идентификаторов задач. По запросу от блока управления очередью помещает идентификатор новой задачи в конец списка или извлекает идентификатор задачи из вершины списка для передачи его в ЦП.
Блок управления свободными ЦП – каждый ЦП, оказываясь свободным, формирует на соответствующем вывод сигнал «Свободен». Данный блок принимает подобные сигналы от всех ЦП в системе, анализирует количество свободных ЦП, и определяет по схеме приоритетов какой из свободных ЦП должен быть выбран для обработки задачи.
Блок синхронизации – основной блок в системе, в функции которого входит анализ информации о том: есть ли ожидающие задачи в системе и есть ли свободные ЦП, которые можно назначить для обработки этих задач. Данный блок осуществляет взаимодействие с каждым ЦП в системе и отвечает за передачу идентификатора задачи свободному ЦП, выбранному для обслуживания в соответствии с определенной схемой приоритетов.
Алгоритм разделения загрузки представляет наиболее простой и эффективный способ планирования, т. к. обладает рядом достоинств: загрузка распределяется равномерно между ЦП, обеспечивая отсутствие простоев ЦП при наличии готовых к выполнению задач; простота представления и высокая степень понятности алгоритма функционирования планировщика, заключающаяся в том, что когда ЦП освобождается, он вызывает функцию назначения задач из ОС.
Результаты моделирования системы показаны на рисунке 3. Задачи поступают в систему с периодичностью в 5 тактов, любой ЦП обслуживает задачу на протяжении 32 тактов. ДЗ успевает принимать и назначать все поступающие задачи. Он не перегружается ни на каком отрезке времени, способен обрабатывать и более интенсивный поток задач.

Рисунок 3. Временные диаграммы работы системы
Аппаратный буфер и ДЗ реализованы на языке VHDL и входят в состав РВС, базирующийся на ПЛИС Cyclone 4 фирмы Altera, на данных интегральных схемах конфигурируются софт-микропроцессорные ядра NIOS II, одна из ПЛИС используется для реализации ДЗ и аппаратного буферного устройства, ОЗУ 1 Гб состоит из двух банков памяти по 512 Мб. РВС – ВС, элементная база, которой состоит из множества соединенных между собой ПЛИС большой интеграции, образующих единое вычислительное поле. РВС благодаря гибкой архитектуре системы обеспечивает реальную производительность при решении вычислительно трудоемких задач, к которым относятся задачи цифровой обработки сигнала. РВС предназначена для конфигурирования архитектуры под различные классы задач цифровой обработки сигнала. Данные задачи находят применение в следующих отраслях: образование – обучение и исследование ВВС, ЦОС; медицина – обработка графической информации и обработка базы данных больниц; геоинформационные системы – оцифровка карт, обработка картографических данных и т. д.; охранные системы – интеллектуальные охранные системы; военные структуры – шифраторы каналов передачи информации, автоматические системы наведения и т. д.
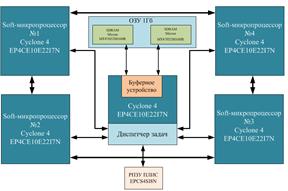
Рисунок 4. Схема РВС
Введение в РВС аппаратной реализации ДЗ позволит повысить производительность и значительно снять проблему временных потер при планировании процессов и задач, в свою очередь аппаратный буфер позволит увеличить пропускную способность в подсистеме «процессор-память», что положительно повлияет на производительность системы в целом.
Список литературы:
- Суворова Е.А., Шейнин Ю.Е. Проектирование цифровых систем на VHDL. – СПб.: БХВ-Петербург, 2003. – 576 с. ISBN: 5-94157-189-5.
- Таненбаум Э., Бос Х. Современные операционные системы. – СПб.: Питер, 2015. – 1120 с. ISBN: 978-5-496-01395-6.
дипломов