
Статья опубликована в рамках: LI Международной научно-практической конференции «Технические науки - от теории к практике» (Россия, г. Новосибирск, 26 октября 2015 г.)
Наука: Технические науки
Секция: Информатика, вычислительная техника и управление
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
АППАРАТНАЯ ПОДДЕРЖКА КАТАЛИЗАТОРА ДЛЯ РЕАЛИЗАЦИИ МЕХАНИЗМА ОЧЕРЕДЕЙ СООБЩЕНИЙ В МНОГОПРОЦЕССОРНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМАХ
Мартышкин Алексей Иванович
канд. техн. наук, доцент кафедры Вычислительных машин и систем
Пензенского государственного технологического университета,
РФ, г. Пенза
E-mail: Alexey314@yandex.ru
Карасева Елена Александровна
магистрант кафедры Вычислительных машин и систем
Пензенского государственного технологического университета,
РФ, г. Пенза
E-mail:
HARDWARE SUPPORT CATALYST FOR IMPLEMENTING THE MECHANISM OF MESSAGE QUEUES IN MULTIPROCESSOR COMPUTER SYSTEMS
Alexey Martyshkin
candidate of Science, assistant professor Department of Computational Systems and Machines
of Penza State Technological University,
Russia, Penza
Elena Karaseva
master student Department of Computational Systems and Machines
of Penza State Technological University,
Russia, Penza
Работа выполнена при финансовой поддержке стипендии Президента РФ молодым ученым и аспирантам на 2015—2017 гг. (СП-828.2015.5)
АННОТАЦИЯ
В статье повествуется об обмене между параллельными процессами в многопроцессорной вычислительной системе, недостатках программных реализаций этого механизма и предлагается аппаратный катализатор, выполняющий данную функцию. Описывается его архитектура и интерфейс взаимодействия с системой. В заключении приводятся результаты моделирования, и выводы.
ABSTRACT
The article tells about the exchange between the parallel processes in a multiprocessor computer system, the shortcomings of software implementations of this mechanism and offers hardware catalyst that performs this function. It describes its architecture and interface to the system. In the end of article presents the results of modeling and conclusions.
Ключевые слова: многопроцессорная вычислительная система; параллельные процессы; семафор; разделяемая память; аппаратный буфер; счетчик; аппаратный катализатор.
Keywords: a multiprocessor computing system; concurrent processes; semaphores; shared memory; hardware buffer; counter; hardware-based catalyst.
При распараллеливании программ всегда возникают взаимодействия между процессами, проявляющиеся в виде обмена между параллельными ветвями алгоритма или параллельными процессами. Для такого обмена существует целый ряд механизмов, таких как разделяемая память, семафоры и другие средства взаимодействий между процессами [1]. Все перечисленные механизмы реализуются программно в операционной системе (ОС). В случае неэффективной реализации механизмов обмена, производительность системы снижается, а время отклика возрастает. Поэтому перенесение функций межпроцессного обмена из программной в аппаратную часть ОС может существенно повысить ее производительность, снизив время на обмен данными между процессами и освободив больше процессорного времени для прикладной задачи.
В статье используется алгоритм управления взаимодействующими процессами при обмене сообщениями в задаче «производители-потребители». Здесь задача синхронизации процессов решается посредством использования монитора, запрещающего одновременный доступ двух или более процессов к общему ресурсу (ОР), представленному в виде кольцевого буфера, тем самым обеспечивается бесконфликтный обмен данными между процессом производителем и процессом потребителем [1].
В общем виде структурная схема аппаратного катализатора для реализации механизма очередей сообщений представлена на рис. 1.
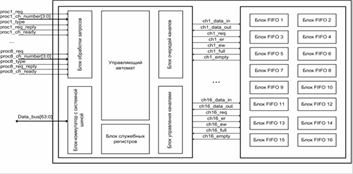
Рисунок 1. Структурная схема аппаратного катализатора
Блоки FIFO. Каждый из 16 блоков FIFO представляет собой кольцевой буфер размером 1024 записи. Запись в буфер производится по принципу «первый вошел первый вышел». В каждом канале имеется 4 счетчика: счетчик, хранящий значение «головы» буфера. При записи его значение увеличивается на единицу; счетчик, хранящий значение «хвоста» буфера. При чтении его значение увеличивается на единицу; счетчик, подсчитывающий общее количество занятых ячеек в буфере. Его начальное значение равно нулю, при каждой записи оно увеличивается на единицу, а при каждом чтении из буфера уменьшается на единицу; счетчик, подсчитывающий общее количество пустых ячеек в буфере. Начальное значение счетчика равно 1024, при каждой записи оно уменьшается на единицу, а при каждом чтении увеличивается на единицу.
Блоки FIFO соединены с блоком управления каналами внутренним интерфейсом, состоящим из следующих сигналов: Ch_req — сигнал запроса; Ch_er — сигнал разрешения чтения; Ch_ew — сигнал разрешения записи; Ch_empty — сигнал, извещающий управляющее устройство о пустоте канала; Ch full — сигнал, извещающий управляющее устройство о заполненности канала; Ch_data_in — входная шина данных (запись); Ch_data_out — выходная шина данных (чтение).
Блок управления каналами. Этот блок хранит состояние каждого счетчика и на основе этих данных принимает решение, возможна ли запрошенная центральным процессором (ЦП) операция или нет.
Блок очередей каналов. В этом блоке содержатся буферы, в которых хранятся запросы для каждого канала устройства, а также идентификаторы ЦП, произведших запрос. Когда устройство управления проверяет очереди каналов, блок очередей каналов выдает не только сам запрос, но и идентификатор ЦП, подавшего этот запрос.
Блок обработки запросов. Этот блок соединяется с каждым ЦП линией запроса, когда на нее поступает активный сигнал, происходит фиксация запроса и идентификатора ЦП, запросившего обмен. Эти данные передаются в блок очередей каналов, где хранятся до выборки устройством управления. В случае, когда ЦП подал запрос, но при этом уже находится в одной из очередей каналов, запрос не обрабатывается, а передается напрямую в устройство управления для дальнейшей обработки.
Блок коммутации. Данный блок реализует взаимодействие устройства с системной шиной и производит передачу всей необходимой информации в устройство.
Блок служебных регистров. Сюда входят различные буферные регистры и регистры, необходимые для работы устройства управления. Например, шестнадцать регистров ch_cur_proc, в которых хранятся идентификаторы ЦП, обрабатываемых каждым каналом устройства.
Устройство управления. Устройство управления реализует основной алгоритм работы устройства. Каждое состояние соответствует одному из этапов в алгоритме обмена сообщениями. Так один из каналов может находиться в состоянии ожидания поступления заявки, другой в состоянии обработки этой заявки, а третий уже обмениваться информацией с ЦП. Такая параллельная организация устройства управления позволяет добиться лучших показателей задержки, чем классическая схема с программной реализацией алгоритмов межпроцессного обмена.
Было произведено моделирование аппаратного катализатора на языке VHDL. На рис. 2 представлен общий вид функциональной схемы моделирования.
Системный интерфейс представлен следующими сигналами: Proc_rec — выставляя данный сигнал в единицу ЦП подает запрос на обмен; Proc_ch_num — ЦП выставляет номер запрашиваемого канала; Proc_type — сигнал типа операции (0 — запись, 1 — чтение); Proc_req_reply — сигнал подтверждения обмена, поступающий от аппаратного катализатора к ЦП. Data_bus — шина данных, состоит из двух однонаправленных шин (data_bus_in и data_bus_out). Для обмена с катализатором ЦП должен выставить единичный сигнал Proc_rec, а на Proc_ch_num — номер канала устройства. Когда подходит очередь ЦП на обмен, катализатор выставляет единичный сигнал Proc_req_reply. Восприняв этот сигнал, ЦП захватывает системную шину и сбрасывает сигнал Proc_rec в нуль. После чего производится обмен данными.
Управляющий арбитр был реализован по приоритетной схеме: первый ЦП обладает наивысшим приоритетом, последний — низшим.
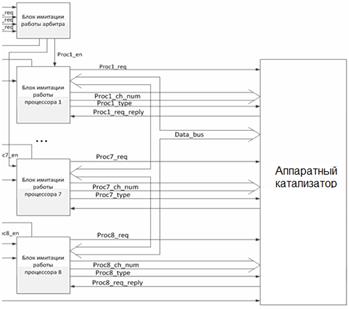
Рисунок 2. Общий вид функциональной схемы моделирования
В результате моделирования получены следующие результаты: процесс записи занимает 9 тактов, а чтения 12 тактов. Для сравнения программная реализация каналов FIFO затрачивает несколько тысяч тактов шины на данные операции (около 5000 тактов). Однако эти значения можно использовать лишь как приблизительные, так как моделирование производилось с использованием имитации работы ЦП и системного арбитра, и в модели не учитывался обмен ЦП с оперативной памятью.
Список литературы:
- Таненбаум Э., Бос Х. Современные операционные системы. — СПб.: Питер, 2015. — 1120 с.
дипломов