
Статья опубликована в рамках: XIV Международной научно-практической конференции «Наука вчера, сегодня, завтра» (Россия, г. Новосибирск, 07 июля 2014 г.)
Наука: Технические науки
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
ПРОБЛЕМНО-ОРИЕНТИРОВАННОЕ АВТОРЕФЕРИРОВАНИЕ КАК ИНСТРУМЕНТ ПОИСКА ДАННЫХ И ЗНАНИЙ
Симанков Владимир Сергеевич
д-р техн. наук, профессор, Кубанский государственный технологический университет, профессор кафедры Компьютерных технологий и информационной безопасности, РФ, г. Краснодар
E-mail : vs@simankov.ru
Толкачев Демид Максимович
аспирант кафедры Компьютерных технологий и информационной безопасности, Кубанский государственный технологический университет, РФ, г. Краснодар
E-mail : Gendalf373@rambler.ru
Для эффективного принятия любых управленческих решений необходимо наличие достаточного объёма данных и знаний, касающихся решаемой проблемы. Лицо, принимающее решения (ЛПР), может не обладать всеми необходимыми сведениями, поэтому в качестве источника актуальной информации часто используют сеть Интернет, чья роль в современном обществе неуклонно возрастает.
Однако, характеризуясь наличием огромного объёма данных и знаний по любым предметным областям, Интернет, в то же время, содержит столь же большой объём неактуальной информации и «информационного шума». Поисковые системы стараются не включать ссылки на источники с нерелевантными сведениями в результаты поиска, но многие сайты содержат как полезную информацию, так и неактуальные данные. Отсюда возникает задача вычленения релевантных сведений из большого объёма прочей информации, и в настоящее время данная задача не нашла окончательного решения.
Существует ряд подходов, которые позволяют получить краткую информационную выжимку из веб-источника, содержащую наиболее важные данные и знания. К ним относятся сниппеты, ассоциативный поиск и автореферирование.
Современные поисковые системы, такие как Google и Яндекс, на большинство запросов выдают просто набор ссылок, отсортированных в порядке релевантности запросу. Под каждой ссылкой располагается сниппет — некий фрагмент текста из источника, содержащий некоторые из ключевых слов. Если необходимо получить короткий ответ на вопрос, в ряде случаев он может содержаться в сниппете. В других случаях сниппет позволяет лишь составить некоторую предварительную оценку источника, а не получить основную информацию из него. Отсюда следует, что механизм сниппетов в чистом виде непригоден для поиска данных и знаний.
Механизм так называемого ассоциативного поиска по документу предполагает выдачу не только фраз и предложений, где содержатся ключевые слова, но и где есть слова, определённым образом ассоциирующиеся с ключевыми. Использование ассоциативного поиска по документу в некоторых случаях, как и сниппеты, позволит получать ответы на вопрос [2], однако его возможности ограничены выдачей некоторого количества несвязных фраз и предложений, поэтому он также не является наиболее эффективным средством решения рассматриваемой проблемы.
Автоматическое реферирование, или автореферирование, — это составление кратких изложений материалов, аннотаций или дайджестов, т. е. извлечение наиболее важных сведений из одного или нескольких документов, и генерация на их основе лаконичных и информационно ёмких отчётов [3]. Потребность в автореферировании возникла в компьютерную эру в связи со значительным возрастанием объёмов информации. Классическое автореферирование предполагает составление информационного «портрета» документа, выжимку его основной сути. Если документ посвящён решению какой-либо проблемы, в его автореферате с большой долей вероятности будет содержаться это решение. Однако далеко не всегда поисковые системы выдают на запрос только те веб-страницы, которые посвящены текущему вопросу или проблеме ЛПР. В некоторых случаях таких страниц не будет вовсе, в то время как требуемые данные и знания будут содержаться в виде отступления от основной темы, рассмотренного примера, частного случая и пр. Кроме того, веб-страницы, помимо html-тэгов, содержат ещё и много смыслового информационного шума, что существенно затрудняет работу с ними для систем, реализующих классические алгоритмы автореферирования, предназначенные для работы с грамотным текстом.
Таким образом, чтобы создать наиболее универсальное средство получения данных и знаний из веб-источников, предложим комбинацию классического автореферирования, ассоциативного поиска и сниппетов. Назовём её проблемно-ориентированным автореферированием (ПОА).
Можно предложить следующий алгоритм ПОА (рисунок 1).
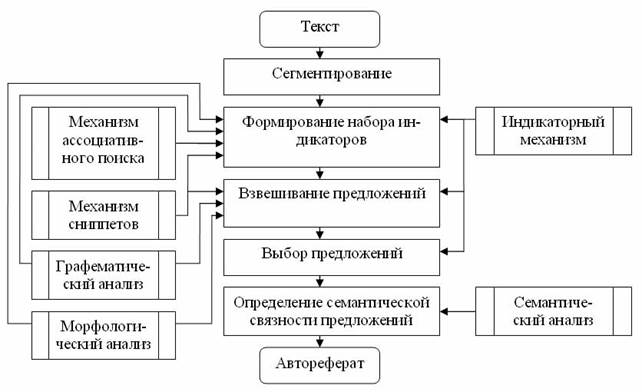
Рисунок 1. Алгоритм проблемно-ориентированного автореферирования
Основу ПОА будет составлять индикаторный метод квазиреферирования. Поскольку статистический метод предполагает выделение предложений из текста, исходя из наличия в них наиболее часто встречающихся слов, а позиционный метод придаёт предложениям веса в зависимости от места расположения предложений в тексте, именно индикаторный метод, использующий определённые словари для маркировки наиболее значимых предложений, наилучшим образом подходит для поиска данных и знаний по конкретной проблеме.
Набор индикаторов в ПОА, в отличие от индикаторного метода квазиреферирования, будет зависеть от вопроса или проблемы и включать следующие основные группы, расположенные в порядке уменьшения их важности:
·основы слов (за исключением союзов, предлогов, частиц и междометий) из запроса (описания проблемы);
·основы слов и словосочетаний из универсального словаря «действий»; такой словарь должен содержать основы слов, с существенной долей вероятности указывающих на то, что в предложении говорится о каких-либо действиях, путях решения проблемы или выводах, например: необходимо, следует, выполнить, решается, таким образом, сделать и т. д.;
·основы синонимов и гипонимов слов из описания проблемы; для этого нужно наличие словаря синонимов и гипонимов; данная группа, в отличие от первых двух, может быть пустой;
·основы слов из тематического словаря, т. е. словаря, составленного специально для определённой области знаний и содержащего наиболее важные слова и термины, характерные для данной области; наличие такого словаря повысит эффективность ПОА при заполнении базы знаний по определённой теме; эта группа также может быть пустой.
Также могут использоваться дополнительные словари индикаторов. Такие словари для ПОА научного текста можно взять из [1].
Основной независящий от вопроса набор индикаторов — словарь «действий» — имеет смысл сформировать с помощью самообучающегося модуля, подав на его вход документы, содержащие высокую концентрацию рекомендаций и описаний способов решения проблем. Самообучающийся модуль определит частоту встречаемости тех или иных слов и выявит наиболее распространённые, из которых можно будет сформировать словарь «действий» с весами, вычисляемыми по формуле:
![]() , (1)
, (1)
где: w — вес,
f — количество появлений слова в массиве документов для обучения.
Вес предложения, в свою очередь, можно будет вычислить так:
![]() , (2)
, (2)
где: wsi — вес i-ого предложения,
m — число словарей индикаторов,
wdj — вес j-ого словаря (определяет, насколько важен словарь в целом),
l — число встречающихся в i-ом предложении различных индикаторов из j-ого словаря,
wjk — вес k-ого индикатора в j-ом словаре,
ck — число появлений k-ого индикатора в i-ом предложении.
В результате проведённого исследования можно сделать следующие выводы:
·Для получения данных и знаний из веб-источников целесообразно использовать комбинацию классического автореферирования, ассоциативного поиска и сниппетов — проблемно-ориентированное автореферирование.
·Разработан общий алгоритм проблемно-ориентированного автореферирования на основе индикаторных методов квазиреферирования с использованием графематического, морфологического и семантического анализов, а также механизмов ассоциативного поиска и сниппетов.
Список литературы:
1.Анастасия Дыбина. Разработка текстовой базы на основе анализа структуры научного текста. International Journal "Information Technologies & Knowledge" Vol.6, Number 1, 2012. — pp. 93—99.
2.Виктор Демидов. Ассоциативный поиск VisualWorld [Электронный ресурс] — Режим доступа. — URL: http://www.kv.by/index2007270603.htm (дата обращения 03.07.2014).
3.Ландэ Д.В. Поиск знаний в Internet. Профессиональная работа.: Пер. с англ. М.: Издательский дом «Вильямс», 2005. — 272 с.
дипломов