
Статья опубликована в рамках: XXXIV Международной научно-практической конференции «Инновации в науке» (Россия, г. Новосибирск, 30 июня 2014 г.)
Наука: Технические науки
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
ИСПОЛЬЗОВАНИЕ ВОЗМОЖНОСТЕЙ МНОГОПРОЦЕССОРНОЙ ОБРАБОТКИ ДАННЫХ ПРИ РЕАЛИЗАЦИИ АЛГОРИТМОВ КЛАССИФИКАЦИИ И ДЕШИФРАЦИИ ИЗОБРАЖЕНИЙ
Прадун Дмитрий Васильевич
научный сотрудник ГНУ «Объединенный институт проблем информатики Национальной академии наук Беларуси», Белоруссия, г. Минск
E-mail:
USE OF THE MULTIPROCESSOR DATA PROCESSING CAPABILITIES WHEN IMPLEMENTING THE ALGORITHMS OF PATTERN RECOGNITION AND DECODING OF IMAGES
Dmitry Pradun
researcher of SSI “The United Institute of Informatics Problems of the National Academy of Sciences of Belarus”, Belarus, Minsk
АННОТАЦИЯ
Целью данной работы является демонстрация примеров программного решения по организации распределенных вычислений в многопроцессорных системах с использованием библиотеки Intel TBB при решении задач классификации и дешифрации космических и аэроснимков. Приводится общая схема распараллеливания алгоритмов классификации при их программной реализации с помощью библиотеки Intel TBB. Приводится сравнение показателей производительности параллельных и последовательных режимов алгоритмов классификации. Приводятся результаты параллельной модификации алгоритма выявления теней с использованием энтропийного метода бинаризации. Проводится анализ результатов выполнения параллельной и последовательной версии алгоритма.
ABSTRACT
The purpose of this paper is to demonstrate examples of software solution for distributed computing organization in multiprocessor systems using Intel TBB library when solving the tasks of classification and decoding of satellite images and aerophotos. General scheme of pattern recognition algorithm paralleling is given for their software implementation using Intel TBB library. Performance measures of parallel and subsequent modes of pattern recognition algorithms are compared. The results of parallel modification of shadow detection algorithm using the entropy-based thresholding method are displayed. The results of parallel and subsequent algorithm version execution are analyzed.
Ключевые слова: многопроцессорная обработка; классификация; поиск теней; Intel TBB.
Keywords: multiprocessor processing; classification; shadow detection; Intel TBB.
1. Параллельная обработка в процессе классификации изображений
Практическая реализация процесса классификации изображений большого размера часто сталкивается со следующими основными проблемами [1—4]:
1) чрезмерно большие объемы исходных данных, которые необходимо обработать;
2) слишком большие данные обучающих выборок. Данная проблема особенно актуальна для классификаторов с обучением, таких как метод опорных векторов (SVM), байесовский классификатор и т. д.
Подобные проблемы могут быть частично решены с помощью определенной алгоритмической модификации методов классификации. В качестве примера будет использован стандартный классификатор Байеса.
Пусть исходное изображение имеет ![]() цветовых слоев, а
цветовых слоев, а ![]() — набор классов, к которым надо отнести предварительно выделенные объекты изображения. Тогда алгоритм классификации может быть описан следующими основными этапами обработки каждого слоя
— набор классов, к которым надо отнести предварительно выделенные объекты изображения. Тогда алгоритм классификации может быть описан следующими основными этапами обработки каждого слоя ![]() .
.
Этап 1. Кластеризация слоя ![]() с помощью нечеткой логики на основе алгоритма Fuzzy C-means (FCM-алгоритма) [5]. В результате кластеризации на выходе имеем информацию о кластерах
с помощью нечеткой логики на основе алгоритма Fuzzy C-means (FCM-алгоритма) [5]. В результате кластеризации на выходе имеем информацию о кластерах ![]() изображения:
изображения:
· значение псевдоцвета выделенного кластера ![]() ;
;
· список пикселов, которые вошли в данный кластер.
Этап 2. Для каждого кластера ![]() , выделенного на слое
, выделенного на слое ![]() , выполняется байесовская классификация, определяющая, к какому классу относится тот или иной кластер (объекты) изображения. Для вычисления дискриминантной функции используется формула из работы [1]. Значения центральных моментов вычисляются на основе базы обучающих выборок, которая представляет собой список следующего вида для каждого из заданных классов:
, выполняется байесовская классификация, определяющая, к какому классу относится тот или иной кластер (объекты) изображения. Для вычисления дискриминантной функции используется формула из работы [1]. Значения центральных моментов вычисляются на основе базы обучающих выборок, которая представляет собой список следующего вида для каждого из заданных классов:
<индекс пиксела>:<значение интенсивности на слое 1>,…,<значение интенсивности на слое L>
Этап 3. После обработки всех кластеров текущего цветового слоя ![]() сохраняется информация о принадлежности каждого кластера и входящих в его состав пикселов тому или иному классу.
сохраняется информация о принадлежности каждого кластера и входящих в его состав пикселов тому или иному классу.
За счет использования метода кластеризации и обработки каждого цветового слоя отдельно друг от друга можно добиться определенного уменьшения объема оперативной памяти, которая необходима для хранения исходных, промежуточных и выходных данных. Тем не менее, актуальными остаются следующие вопросы:
1) снижение времени, необходимого для загрузки обучающих выборок и расчета математических ожиданий и дисперсий;
2) уменьшение объема оперативной памяти, необходимой для хранения загруженной базы обучающих выборок.
Для решения подобных вопросов может быть использована библиотека Intel TBB [6]. Так как база обучающих выборок представляет собой набор текстовых файлов, в которых хранится необходимая информация, ее загрузку можно выполнять параллельно таким образом, чтобы в каждый момент времени на каждом вычислительном ядре обрабатывался один из файлов. Кроме того, вместо того, чтобы загружать базу данных в оперативную память, расчет текущих значений математических ожиданий и дисперсий для каждого из двух классов выполняется во время анализа данных, полученных из файлов базы обучающих выборок (таблица 1).
Таблица 1 .
Показатели производительности алгоритма классификации на основе метода Байеса в последовательном и параллельном режимах
|
Характеристики изображения |
Время выполнения* |
Размер обучающей выборки цветового слоя, Мб |
Объем оперативной памяти, Мб |
||
|
последовательный режим |
параллельный режим |
последовательный режим |
параллельный режим |
||
|
3 цветовых слоя, 500х358 пикселов |
7 мин 8 сек 270 мс |
2 мин 12 сек 725 мс |
~ 51,0 |
~58,5 |
~ 23,9 |
|
3 цветовых слоя, 919х840 пикселов |
9 мин 9 сек 498 мс |
2 мин 27 сек 864 мс |
~ 518,8 |
~ 448,9 |
~ 24,3 |
*Genuine Intel(R) CPU 2 Core 1,8 ГГц, 2 Гбайт ОЗУ
2. Параллельная модификация алгоритма выявления теней
Пусть имеется цветное RGB-изображение размером ![]() , на котором имеются тени объектов, полученные в результате аэро- или космической съемки [7]. Для выполнения более эффективного и быстрого анализа изображение переводится в цветовую модель YUV, которая состоит из следующих компонент:
, на котором имеются тени объектов, полученные в результате аэро- или космической съемки [7]. Для выполнения более эффективного и быстрого анализа изображение переводится в цветовую модель YUV, которая состоит из следующих компонент:
1) Y — яркостная составляющая пиксела;
2) U и V — цветоразностные составляющие пиксела, необходимые для восстановления требуемого цвета при обратной конвертации.
В большинстве случаев для определенного Y-слоя изображения диапазон значений пикселов данной составляющей меньше чем [0;255], что чаще всего усложняет дальнейший процесс анализа яркостной составляющей снимка. Поэтому следующим шагом алгоритма является так называемое расширение гистограммы Y-компоненты до диапазона [0;255].
После этого строится маска теней исходя из значений Y-компоненты. Для этого сначала вычисляется порог бинаризации изображения ![]() с помощью энтропийного метода Капура [8, 9]. Результаты бинаризации с помощью метода Капура используются для определения пикселов, принадлежащих теням, по следующей схеме:
с помощью энтропийного метода Капура [8, 9]. Результаты бинаризации с помощью метода Капура используются для определения пикселов, принадлежащих теням, по следующей схеме:
|
(1) |
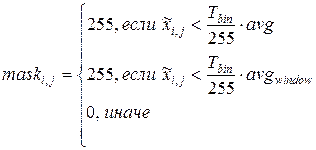 ,
,
где: ![]() — значение маски теней в точке
— значение маски теней в точке ![]() ;
;
![]() — среднее значение яркости Y-слоя;
— среднее значение яркости Y-слоя;
![]() — среднее значение яркости в заданном окне
— среднее значение яркости в заданном окне ![]() .
.
Наибольшие временные затраты при работе алгоритма будут наблюдаться в процессе итерационного уменьшения размера окна ![]() , в котором выполняется анализ пикселов всего изображения. Поэтому именно эта часть алгоритма была подвержена распараллеливанию с помощью библиотеки Intel TBB. Заметим, что при этом сам процесс обработки и анализа пикселов при обходе заданным окном не претерпел никаких алгоритмических изменений, т. е. выполнялся согласно формуле (1). Реализация параллельной версии алгоритма [7] показывает свое существенное преимущество перед последовательной версией в части времени выполнения процесса обработки (таблица 2).
, в котором выполняется анализ пикселов всего изображения. Поэтому именно эта часть алгоритма была подвержена распараллеливанию с помощью библиотеки Intel TBB. Заметим, что при этом сам процесс обработки и анализа пикселов при обходе заданным окном не претерпел никаких алгоритмических изменений, т. е. выполнялся согласно формуле (1). Реализация параллельной версии алгоритма [7] показывает свое существенное преимущество перед последовательной версией в части времени выполнения процесса обработки (таблица 2).
Таблица 2 .
Реализация алгоритма поиска теней в последовательной и параллельной версиях
|
Характеристики изображения |
Время выполнения* |
|
|
последовательная версия |
параллельная версия |
|
|
3 цветовых слоя, 554х357 пикселов |
7 мин 17 сек 473 мс |
1 мин 56 сек 49 мс |
|
3 цветовых слоя, 639х423 пикселов |
10 мин 30 сек 400 мс |
3 мин 2 сек 583 мс |
* Intel(R) Core(TM)2 Quad CPU Q9400 2,66 ГГц, 4 Гбайт ОЗУ
Таким образом, использование программной библиотеки Intel TBB для реализации блочно-параллельной обработки изображений показывает свое преимущество перед последовательной реализацией тех или иных алгоритмов тематической обработки космической информации. Существенное сокращение времени обработки исходной информации позволяет использовать данную библиотеку не только при реализации простейших алгоритмов предварительной и тематической обработки данных (вычисление градиента, бинаризация, фильтрация и т. д.), но и в более сложных методах анализа космической информации, в частности, классификации и дешифрации многоспектральных изображений.
Список литературы:
1.Гонсалес Р. Цифровая обработка изображений / Р. Гонсалес, Р. Вудс. М.: Техносфера, 2005. — 1072 с.
2.Методы компьютерной обработки изображений / М.В. Гашников [и др.]; под.ред. В.А. Сойфера. 2-е изд., испр. М.: ФИЗМАТЛИТ, 2003. — 784 с.
3.Theodoridis S. Pattern Recognition: second edition / S. Theodoridis, K. Koutroumbas. Athens, Greece: Elsevier Academic Press, 2003. — 689 pp.
4.Ту Дж. Принципы распознавания образов / Дж. Ту, Р. Гонсалес; под ред. Ю.И. Журавлева: пер. с англ. И.Б. Гуревича. М.: Изд-во «Мир», 1978. — 413 с.
5.Прадун Д.В. Блочно-параллельная кластеризация изображений на основе нечеткой логики / Д.В. Прадун, А.А. Кравцов // Пятый Белорусский космический конгресс: материалы конгресса. В 2 т. (25—27 октября 2011 года, Минск). Минск: ОИПИ НАН Беларуси, — 2011. — Т. 2. — C. 47—53.
6.Threading Building Blocks Documentation [Electronic resource]. Mode of access – [Электронный ресурс] — Режим доступа. — URL: http://www.threadingbuildingblocks.org/documentation (Date of access 05.06.2011).
7.Прадун Д.В. Алгоритм автоматического определения теней с использованием энтропийного метода бинаризации изображений / Д.В. Прадун, А.А. Мамчич // Информатика. — 2012. — № 2(34). — С. 12—18.
8.Kapur J.N. A new method for gray-level picture thresholding using entropy of the histogram / J.N. Kapur, P.K. Sahoo, A.K.C. Wong // Graph. Models Image Process. — 1985. — Vol. 29. — P. 273—285.
9.Sezgin M. Survey over image thresholding / M. Sezgin, B. Sankur // Journal of Electronic Imaging. — 2004. — Vol. 13, — № 1. — P. 146—165.
дипломов