
Статья опубликована в рамках: XXIX Международной научно-практической конференции «Инновации в науке» (Россия, г. Новосибирск, 29 января 2014 г.)
Наука: Технические науки
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

ПРОГРАММА «СЕГМЕНТАЦИЯ И КЛАСТЕРИЗАЦИЯ РЫНКА IT»
Афанасьева Татьяна Васильевна
д-р техн. наук, доцент, Ульяновский государственный технический университет, РФ, г. Ульяновск
E-mail: tv.afanasjeva@gmail.com
Сибирев Иван Валерьевич
студент, Ульяновский государственный технический университет, РФ, г. Ульяновск
E-mail:
THE PROGRAM “SEGMENTATION AND CLUSTERING OF MARKET IT”
Afanasieva Tatyana Vasilevna
doctor of technical Sciences, associate Professor, Ulyanovsk state technical University, Russia, Ulyanovsk
Sibirev Ivan Valerievich
student, Ulyanovsk state technical University, Russia, Ulyanovsk,
АННОТАЦИЯ
В статье представлен программный продукт «Кластеризация, сегментация IT рынка», который можно использовать для сегментирования рынка IT, для обработки данных и их анализа, группировки, распознавания и представления в удобном для пользователя виде. Потребителями программного продукта могут выступить экономисты, социологи, фирмы, лица, занимающиеся производством и продажей в сфере IT.
ABSTRACT
The article presents the software product «Clustering, segmentation of the IT-market». The program can be used for segmentation of market IT, for analysis, grouping, recognition and presentation information in convenient form for the user. The program means for economists, sociologists, firms and businessmen in the sector IT.
Ключевые слова: сегментация; кластеризация; нечеткие данные; рынок IT.
Keywords: segmentation; clustering; fuzzy data; the IT market.
Социально-экономические системы в их динамическом развитии характеризуются многомерными данными. Междисциплинарное направление синергетика, изучающие поведение сложных систем, в качестве одного из основных постулатов выдвигает иерархичность данных, характеризующих сложные системы. При анализе информации о сложных системах (экономических, биологических, технических и др.) необходимы обработка и анализ огромных объёмов разнородных данных, важно упорядочить их по иерархическим уровням и произвести группировку, разбиение множества исследуемых объектов и признаков на однородные группы или кластеры. Это позволяет сделать кластерный анализ, впервые применённый в социологии Трионом [9] в 1939 г.
Встаёт проблема автоматизации процесса обработки и анализа информации, необходимости создания простого и доступного программного инструмента для группировки и распознавания данных, произвольно структурированных, и типов данных. Остро возникает проблема представления данных в виде удобном и понятном для пользователя. Необходим программный код, который бы мог выполняться на различном HardWare, без его предварительного переноса на «родной язык» устройства. Актуально использование методов кластерного анализа для численных и нечетких данных.
На сегодняшний день актуальным является развитие методов кластерного анализа (см. [2], [3], [4] и др.), среди которых метод полных связей, метод максимального локального расстояния, метод Ворда, центроидный метод и др. Актуально их применение к решению экономических задач (см. [1], [5] и др.), в частности, сегментации рынка, их программная реализация.
Существует программное обеспечение для кластерного анализа в узких предметных областях, например, “ClusterDelta” позволяет производить анализ данных на бирже, существуют программы для прогноза конъюнктуры рынка и др.
Существуют пакеты программ, реализующие набор методов кластерного анализа данных (“STATISTICA Multivariate Exploratory Techniques”, “MathCad” и др.) В программном пакете “STATISTICA Multivariate Exploratory Techniques” реализованы методы k-средних, иерархической кластеризации и двухвходового объединения. Используются различные метрики расстояний. Эти пакеты рассчитаны на использование профессиональными математиками и в этом их ограничение. Другое ограничение состоит в том, что они не ориентированы на решение задачи кластеризации в условиях неоднородных показателей, при обработке нечетких данных.
На сегодняшний день актуально сочетание кластерного анализа с теорией нечетких множеств (см. [6], [7] и др.), основы которой заложены в 60-е годы американским математиком Латфи Заде. В настоящее время Японией и США активно разрабатываются электронные системы с нечеткими управляющими алгоритмами.
Нами ведется разработка программного инструмента для кластеризации и сегментации данных рынка IT. Используется программный код, который бы мог выполняться на различном HardWare, без его предварительного переноса на «родной язык» устройства. Нами был выбран C#. Код на C# будет работать везде, где установлен «C# .NET».
Выполнена программная реализация методов создания, сохранения, загрузки, обработки кластеров (данных); предусмотрена возможность включения программного продукта в состав более сложной автоматической или автоматизированной системы для экономического анализа. Текущая версия позволяет: визуализировать данные на экране в виде дерева, группировать данные центроидным методом кластерного анализа, выводить на экран результаты анализа данных в виде таблиц, графиков и диаграмм.
В программном продукте используется авторский подход программной реализации методов кластерного анализа, позволяющий получить результат кластеризации в виде иерархической структуры, по которой можно судить о ходе выполнения кластеризации. Сохранение и загрузка данных происходит в формате XML файла, что позволяет пользователю свободно редактировать данные вне программного продукта. Формат XML — прост, удобен, нагляден и понятен пользователю. Предусмотрена возможность использования кластерного анализа в сочетании с другими методами многомерного анализа.
В текущей версии программного продукта производится обработка однородных целочисленных структур данных методами кластерного анализа.
В программном продукте создан класс “Cluster”. Кластер состоит из центра кластера и списка подкластеров. В XML файле кластер имеет следующий синтаксис.
<Cluster Name=" Предприятие № 1">
<Center Count="4" X0="10" X1="50" X2="1000" X3="3" />
<StructureCluster Count="0" />
</Cluster>
Центр кластера — вектор целочисленных значений. Например,
 .
.
<Center Count="4" X0="10" X1="50" X2="1000" X3="3" />
Список подкластеров — это множество, элементы которого — кластеры. Кластер с пустым списком подкластеров называют кластером единичной мощности. В XML файле список подкластеров имеет следующий синтаксис.
<StructureCluster Count="12">
<Cluster Name=" Предприятие № 1">
<Center Count="4"X0="10"X1="50" X2="1000" X3="3" />
<StructureCluster Count="0" />
</Cluster>
<Cluster Name=" Предприятие № 2">
…
</StructureCluster>
В программном продукте данные хранятся в виде экземпляра класса “Cluster”, который имеет иерархическую структуру и рекурсивные методы обработки. Данные в классе “Cluster” структурированы и состоят из «кластера-оболочки» и «рабочей зоны».
Таблица 1.
Схема преобразования данных
|
Загрузка |
Обработка |
Сохранение |
Визуализация |
XML ФАЙЛ |
Cluster |
Cluster |
Cluster |
После загрузки из файла, перед обработкой данных рабочая зона имеет вид списка подкластеров единичной мощности. После обработки данных рабочая зона имеет вид списка подкластеров разных мощностей.
В программном продукте реализованы метрики:
 ;
;![]() ;
;![]() ;
; 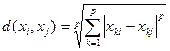 ,
,
где ![]() ,
, ![]() .
.
Зададим расстояние между кластерами как расстояние между их центрами. ![]()
В программном продукте реализован центроидный метод кластерного анализа, в котором расстояние между двумя кластерами определяется как евклидово расстояние между центрами этих кластеров:
 .
.
Кластеризация идет поэтапно. На каждом шагу заменяют два кластера А и В, расстояние между которыми наименьшее, кластером С, для которого A и B — подкластеры. Данный метод обработки реализован рекурсивно. Задание числа кластеров на выходе — критерий остановки метода.
Пример. Дан XML файл.
<?xml version="1.0" encoding="utf-16"?>
<Body>
<Cluster Name="NoName">
<Center Count="0" />
<StructureCluster Count="12">
<Cluster Name=" Предприятие № 1">
<Center Count="4" X0="10" X1="50" X2="1000" X3="3" />
<StructureCluster Count="0" />
</Cluster>
<Cluster Name=" Предприятие № 2">
…
</StructureCluster>
</Cluster>
</Body>
Исходные данные обработаем центроидным методом.
На рисунке 1 представлена визуализация данных до обработки и после обработки.

Рисунок 1. Визуализация данных до и после обработки
Данные, сгруппированные центроидным методом, сохранены в XML файл.
Программный продукт может быть интегрирован в состав более сложной автоматической или автоматизированной вычислительной системы (автоматической системы управления, прогнозирования и др.), размеры которой могут быть в пределах одной машины, локальной, глобальной сети, с оповещением через существующие средства связи (sms, Email и др.).
Ведется разработка следующей версии программного продукта «Кластеризация, сегментация IT рынка», которую можно будет использовать для сегментирования рынка IT, для обработки экономических данных и их анализа, группировки, распознавания и представления в удобном для пользователя виде. Для этого будут применены экономические модели сегментации рынка (Уинда и Кардозы и др.), произведен анализ объектов IT рынка.
Программное обеспечение предполагается использовать для сегментации ИТ-предприятий Ульяновской области по следующим параметрам: объем реализации, прирост объема реализации, количество сотрудников, возраст предприятия, количество клиентов, доля объема продукции для зарубежных клиентов, средний возраст сотрудников и др. Эти данные получены в рамках исследования 2013 года [8].
Программное обеспечение будет адаптировано для экономической терминологии «Кластеризация, сегментация IT рынка». Наряду с обработкой числовых данных станет возможной обработка нечетких данных.
Потребителями данного программного продукта могут выступить экономисты, социологи, фирмы, лица, занимающиеся производством и продажей в сфере IT, которым полезно сегментирование рынка товаров и услуг, структурирование рынка, основанное на неоднородности и нечеткости показателей и критериев. Такой анализ необходим для дифференцированного маркетинга.
Программный продукт был представлен на конкурсе «УМНИК-2013».
Список литературы:
1. Болч Б. Многомерные статистические методы для экономики / Б. Болч, К.Дж. Хуань. Пер. с англ. М.: Статистика, 1979. — 317 с.
2. Дюран Б. Кластерный анализ / Б. Дюран, П. Оделл. М.: Статистика, 1977. — 128 с.
3. Жамбю М. Иерархический кластер-анализ и соответствия. Пер. с фр. / М. Жамбю. М.: Финансы и статистика, 1988. — 342 с.
4. Классификация и кластер. /Под ред. Дж. Райзина. М.: Мир, 1980, — 390 с.
5. Сошникова Л.А., Тамашевич В.Н., Уебе Г., Шефер М. Многомерный статистический анализ в экономике / Л.А. Сошникова, В.Н. Тамашевич, Г. Уебе, М. Шефер. М.: ЮНИТИ-ДАНА, 1999. — 598 с.
6. Ярушкина Н.Г. Основы теории нечетких и гибридных систем. Учебное пособие / Н.Г. Ярушкина. СПБ.: Финансы и статистика, 2004. — 320 c.
7. Ярушкина Н. Г. Интеллектуальный анализ временных рядов / Н.Г. Ярушкина, Т.В. Афанасьева. Ульяновск: УлГТУ, 2010. — 299 с.
8. Ярушкина Н.Г. Исследование ИТ-кластера Ульяновской области / Н.Г. Ярушкина, Т.В. Афанасьева, О.В. Шиняева и др., отв. ред. Т.В. Афанасьева. Ульяновск : УлГТУ, 2013. — 137 с.
9. Tryon R.C. Cluster Analysis. New York: McGraw-Hill. 1939.
дипломов