
Статья опубликована в рамках: XVI Международной научно-практической конференции «Инновации в науке» (Россия, г. Новосибирск, 28 января 2013 г.)
Наука: Технические науки
Скачать книгу(-и): Сборник статей конференции, Сборник статей конференции часть II
- Условия публикаций
- Все статьи конференции
дипломов

ОСОБЕННОСТИ ЗАДАЧИ ПРИМЕНЕНИЯ DATA MINING ДЛЯ ОБНАРУЖЕНИЯ РАЗРУШАЮЩИХ ПРОГРАММНЫХ ВОЗДЕЙСТВИЙ
Комашинский Дмитрий Владимирович
аспирант, Санкт-Петербургский институт информатики и автоматизации РАН (СПИИРАН), г. Санкт-Петербург
Е-mail: komashinskiy@comsec.spb.ru
CHARACTERISTIZING THE USE OF DATA MINING METHODS FOR MALICIOUS SOFTWARE DETECTION
Dmitry Komashinskiy
Ph.D. student, St.Petersburg Institute for Informatics and Automation of the Russian Academy of Sciences (SPIIRAS), St. Petersburg
Работа выполняется при финансовой поддержке РФФИ, программы фундаментальных исследований ОНИТ РАН, Министерства образования и науки Российской Федерации (государственный контракт 11.519.11.4008), Комитета по науке и высшей школе Правительства Санкт-Петербурга, при частичной финансовой поддержке, осуществляемой в рамках проектов Евросоюза SecFutur и MASSIF, а также в рамках других проектов.
АННОТАЦИЯ
Работа посвящена формализации обобщенного описания процесса применения методов Data Mining (DM) в задаче обнаружения разрушающих программных воздействий (РПВ). Для решения задачи использованы элементы методологии SADT, обобщающие основные процедурные аспекты существующих научных работ, посвященных данной предметной области. Определены основные составляющие процесса использования методов DM для обнаружения РПВ и разработана его модель, определеная с точки зрения исследователя.
ABSTRACT
The article is focused on formalizing a generic description of using Data Mining (DM) methods for malware detection. To this end, SADT methodology was adopted for generalizing common procedural aspects described in available papers devoted to the problematic area. The main characteristics of DM usage’s process for malware detection were defined, its model, based on researcher’s point of view, was developed.
Ключевые слова: обнаружение разрушающих программных воздействий; Data Mining; моделирование.
Keywords: Malware detection; Data Mining; modeling.
Введение
Изложенные основы формализованного представления основных фаз жизненного цикла систем обнаружения и идентификации РПВ на основе методов DM [1] были дополнительно детализированы с учетом результатов исследований, опубликованных за предыдущий год. К примеру, следует отметить цикл работ, проведенных в контексте обобщенных многоцелевых исследований применимости DM в области информационной безопасности [2], позволивший прийти к лучшему пониманию общей структуры процессов, выполняемых при формировании систем данного класса.
Модель процесса обучения системы обнаружения РПВ
Процесс обучения системы обнаружения РПВ (Рис. 1.) может быть представлен как последовательность действий (цепочка подпроцессов) ![]() , обеспечивающая получение из обучающего набора данных
, обеспечивающая получение из обучающего набора данных ![]() целевой модели
целевой модели ![]() , построенной на основе пространства атрибутов
, построенной на основе пространства атрибутов ![]() . В дальнейшем пространство атрибутов
. В дальнейшем пространство атрибутов ![]() и работающая в его рамках целевая модель
и работающая в его рамках целевая модель ![]() используются в процессе эксплуатации системы (Рис. 2). Выделенные элементы процесса обучения данных систем могут быть охарактеризованы следующим образом. Подпроцесс извлечения признаков
используются в процессе эксплуатации системы (Рис. 2). Выделенные элементы процесса обучения данных систем могут быть охарактеризованы следующим образом. Подпроцесс извлечения признаков ![]() обеспечивает формирование начального пространства атрибутов
обеспечивает формирование начального пространства атрибутов ![]() , в рамках которого формируется описание
, в рамках которого формируется описание ![]() каждого элемента входного набора данных
каждого элемента входного набора данных ![]() . Формирование
. Формирование ![]() осуществляется за счет использования предварительно выбранной исследователем модели представления объектов
осуществляется за счет использования предварительно выбранной исследователем модели представления объектов ![]() , целью которой является обеспечение единого подхода к рассмотрению элементов множества
, целью которой является обеспечение единого подхода к рассмотрению элементов множества ![]() в рамках выделенного аспекта [3], обеспечивая тем самым преобразование
в рамках выделенного аспекта [3], обеспечивая тем самым преобразование ![]() . Задачей подпроцесса выделения значимых признаков
. Задачей подпроцесса выделения значимых признаков ![]() является оптимизация размерности [4] и эффективности использования начального пространства атрибутов
является оптимизация размерности [4] и эффективности использования начального пространства атрибутов ![]() , на основе которого построено множество описаний элементов входного набора данных
, на основе которого построено множество описаний элементов входного набора данных ![]() с получением новых пространства атрибутов
с получением новых пространства атрибутов ![]() и описания входного набора данных
и описания входного набора данных ![]() . На практике задача оптимизации может быть связана как с выделением
. На практике задача оптимизации может быть связана как с выделением ![]() из
из ![]() , так и с полным или частичным формированием множества
, так и с полным или частичным формированием множества ![]() на основе атрибутов, не входящих в начальное пространство
на основе атрибутов, не входящих в начальное пространство ![]() . Часто в интересах минимизации временных и ресурсных затрат задача конструирования признаков по умолчанию сводится к формированию модели представления объектов
. Часто в интересах минимизации временных и ресурсных затрат задача конструирования признаков по умолчанию сводится к формированию модели представления объектов ![]() таким образом, чтобы оптимизация начального пространства атрибутов не требовала формирования новых.
таким образом, чтобы оптимизация начального пространства атрибутов не требовала формирования новых.
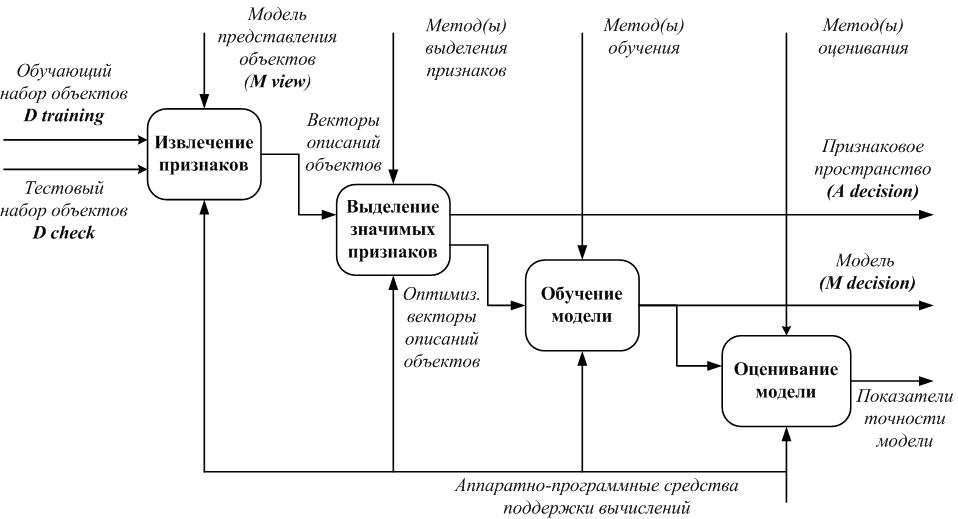
Рисунок 1. Модель процесса обучения систем обнаружения РПВ
Это объясняет фокус данного процесса на использовании определенной при подготовке эксперимента процедуры ![]() ,
, ![]() выделения значимых признаков
выделения значимых признаков ![]() из числа существующих
из числа существующих ![]() . Подпроцесс обучения модели
. Подпроцесс обучения модели ![]() является основополагающим во всем процессе обучения системы и обеспечивает формирование целевой модели
является основополагающим во всем процессе обучения системы и обеспечивает формирование целевой модели ![]() на основе использования оптимизированного набора данных
на основе использования оптимизированного набора данных ![]() применительно к выбранному исследователем методу обучения. Подпроцесс оценивания модели
применительно к выбранному исследователем методу обучения. Подпроцесс оценивания модели ![]() предоставляет возможность получить количественную оценку качества предиктивной способности полученной на предыдущем шаге целевой модели
предоставляет возможность получить количественную оценку качества предиктивной способности полученной на предыдущем шаге целевой модели ![]() на основе тестового набора данных
на основе тестового набора данных ![]() .
.
Модель процесса эксплуатации системы обнаружения РПВ
Процесс эксплуатации эвристической системы обнаружения РПВ может быть представлен как цепочка подпроцессов) ![]() .
.
Рисунок 2. Модель процесса эксплуатации систем обнаружения РПВ
Он использует полученные на этапе обучения пространство атрибутов ![]() для формирования оптимизированного представления объектов множества и целевую модель
для формирования оптимизированного представления объектов множества и целевую модель ![]() . Подпроцесс извлечения признаков
. Подпроцесс извлечения признаков ![]() по своей сути идентичен аналогичному подпроцессу фазы обучения систем обнаружения РПВ. Его основным отличием является то, что извлекаются признаки, относящиеся только к оптимизированному пространству атрибутов,
по своей сути идентичен аналогичному подпроцессу фазы обучения систем обнаружения РПВ. Его основным отличием является то, что извлекаются признаки, относящиеся только к оптимизированному пространству атрибутов, ![]() . Размер множества входящих объектов
. Размер множества входящих объектов ![]() в данном случае не имеет значения и в общем случае
в данном случае не имеет значения и в общем случае ![]() . Целью подпроцесса эксплуатации целевой модели
. Целью подпроцесса эксплуатации целевой модели ![]() является формирование метки класса объектов множества
является формирование метки класса объектов множества ![]() .
.
Заключение
Представленная работа излагает основы результатов моделирования отдельных аспектов жизненного цикла систем обнаружения РПВ на основе методологии SADT. Задачей моделирования является уточнение струкуры процессов обучения и эксплуатации систем обнаружения разрушающих программных воздействий на основе методов Data Mining с точки зрения исследователя. Данные модели позволяют улучшить представление процессов и структуры исследований, проводимых в данной предметной области.
Список литературы
1. Комашинский Д.В., Котенко И.В. Концептуальные основы использования методов Data Mining для обнаружения вредоносного программного обеспечения // Защита информации. Инсайд, № 2, 2010. С. 74—82.
2. Masud M., Khan L., Thuraisingham B. Data Mining Tools for Malware Detection. CRC Press, Taylor & Francis Group, LLC, 2012. 419 с.
3. Komashinskiy D., Kotenko I. Using Low-Level Dynamic Attributes for Malware Detection Based on Data Mining Methods // Proceedings of the 6th International Conference on Mathematical Methods, Models and Architectures for Computer Network Security, Saint-Petersburg, 2012. С. 254—269.
4. Komashinskiy D., Kotenko I. Malware Detection by Data Mining Techniques Based on Positionally Dependent Features // Proceedings of the 18th Euromicro International Conference on Parallel, Distributed and network-based Processing, 2010. С. 617—623.
дипломов