
Статья опубликована в рамках: VII Международной научно-практической конференции «Экономика и современный менеджмент: теория и практика» (Россия, г. Новосибирск, 21 ноября 2011 г.)
Наука: Экономика
Секция: Финансы и налоговая политика
Скачать книгу(-и): Сборник статей конференции, Сборник статей конференции часть II
- Условия публикаций
- Все статьи конференции
дипломов

ЗНАЧИМОСТЬ ПРЕДВАРИТЕЛЬНОГО АНАЛИЗА ДАННЫХ ПРИ ПОСТРОЕНИИ МОДЕЛЕЙ ОБЪЕКТОВ
Сахабетдинов Минзакир Абдулович
к. т. н., профессор УФ ВЗФЭИ, г. Уфа
E-mail: minzakir-s@yandexl.ru
Данная работа выполнялась в рамках гранта РФФИ №11-06-00056-a.
Построение моделей сложных объектов, а таковыми являются часто и экономические объекты в зависимости от глубины описания, в основном базируется на статистической обработке данных. При этом качество результатов и выводов определяется качеством обрабатываемых данных. Причинами появления в статистических массивах ошибочных, выпадающих точек, резко отклоняющихся от большинства точек информационного массива, описывающих данный объект, являются: ошибочные по своей природе данные (например, полученные с использованием ошибочной методики измерений, наблюдений); сознательные искажения данных их авторами (например, указание в налоговых декларациях более низкой налогооблагаемой базы, чем фактическая); случайные ошибки при наборе текста справочника, формировании файлов; использование неадекватных алгоритмов при обработке первичных наблюдений и т. д.
При отработке различных алгоритмов обработки данных требуются большие массивы данных, которым можно доверять. Но даже сейчас, в век Интернета, совсем не просто добыть такие данные в открытом доступе. Автор данной публикации уже несколько раз [2, 3] обращался к данным, содержащимся в монографии [1]. Достоинством этого источника данных является: достаточно большой объем выборки (около 300 точек в семимерном пространстве наблюдений); обработка этих данных авторами монографии одним из модных в настоящее время средств —нейросетевыми пакетами программ. Автор данной публикации пытается пропагандировать классический регрессионный анализ с модификациями с позиции качественной аппроксимации данных наиболее простыми зависимостями, содержащими как можно меньше эмпирических параметров. Очевидно, что чем меньше параметров в эмпирической модели объекта, тем точнее они определяются при фиксированном объеме выборки, тем больше экстраполяционные возможности модели. Когда одни и те же данные обрабатываются альтернативными методами, есть возможность сравнительного анализа этих методов; основные авторы монографии работают в том же коллективе, что и автор данной публикации и доступны для совместного обсуждения различных подходов.
Данные монографии [1] разбиты на три кластера и содержат следующие экономические показатели ряда торговых организаций г. Уфы: x1—сумма основных средств предприятия; x2—себестоимость реализованных товаров, продукции, услуг; x3—среднесписочная численность работающих; x4—сумма оборотных активов предприятия; x5—среднегодовая стоимость облагаемого налогом имущества; x6—коммерческие расходы; y—выручка предприятия.
В наших расчетах использованы ненормированные значения этих переменных, перечисленные в таблицах 4, 5, 6 Приложения 1 монографии [1]. Разбиение всех данных на 3 кластера авторами монографии произведено вынужденно, так как им не удалось с требуемой точностью описать все данные одной нейросетью, причем принцип разбиения данных на кластеры ориентирован на значения моделируемой величины y: точки 1-го кластера имеют значения y = 2,272373…74,797000 (95 точек); точки 2-го кластера имеют значения y= 0,863153…2.250000 (95 точек); точки 3-го кластера имеют значения y= 0,007296…0,829000 (94 точки); Разбиение всех наблюдений мы оставили таким же, как и в монографии [1]. В дальнейших наших расчетах использовались надстройки MSExcel«Пакет анализа» и « Поиск решения»
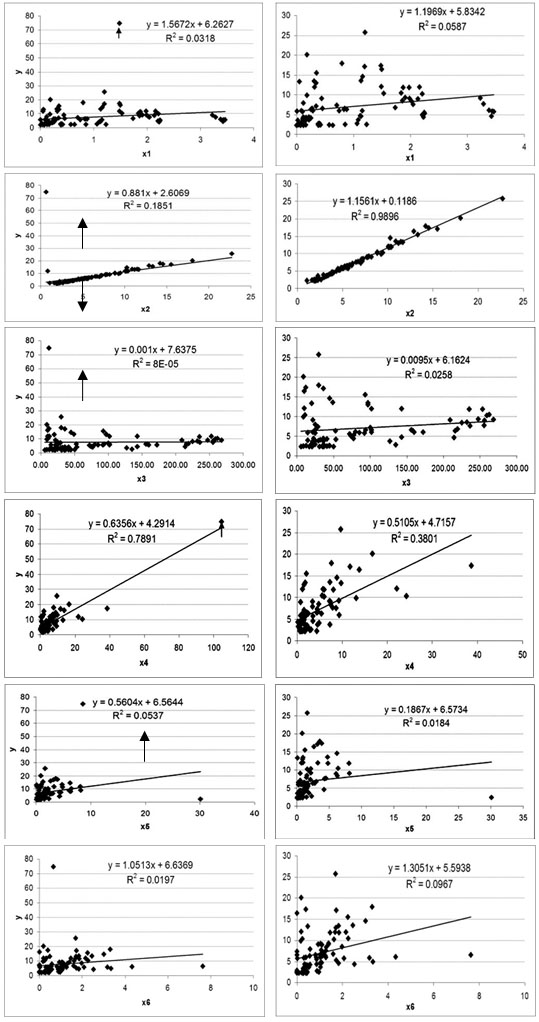
Приступим к анализу точек 1–го кластера. В таблице 1 приведены рисунки, показывающие зависимости y= f(xi) для i=1…6, причем в левой колонке до удаления двух выпадающих (указаны стрелками) точек, а в правой —после.
В таблице 1 приведены графики лишь для наглядности. На самом деле выпадающие точки разыскивались по алгоритму, рекомендованному в [2] и являющимся робастным к выпадающим точкам. Суть этого алгоритма —поиск аппроксимирующего уравнения минимизацией суммы модулей остатков. Решение такой задачи можно легко получить, пользуясь надстройкой MSExcel«Поиск решения».
Таблица 1
Зависимости выручки от факторов до и после удаления выпадающих точек
В таблице 2 даны другие характеристики результатов обработки данных этого кластера.
Таблица 2
Значения коэффициентов корреляции между моделируемыми величинами до и после удаления выпадающих точек

Итак, какие выводы можно делать из изучения материалов таблиц 1 и 2. Удаление всего лишь двух выпадающих точек привело к следующим результатам: 1 —для зависимости y= f(x2) коэффициент детерминации R2= 0,185 до удаления двух выпадающих точек и R2= 0,990 после. 2—замене наиболее сильно влияющего на моделируемую величину фактора x4на фактор x2; 3 —факторы x2, x4были связаны весьма слабо, а стали почти коллинеарными и, как следствие, стало невозможным их одновременно включать в уравнение регрессии; 4 —по статистическим тестам выходит, что моделируемая величина yзависит лишь от одного фактора x2(коэффициент детерминации соответствующего уравнения R2= 0,997!!!); 5 —описание этих данных сложными нейросетями в монографии [1], по-видимому, можно объяснить, во-первых, попыткой хорошего описания всех данных, включая и выпадающие, а во-вторых, неудачным выбором активационных функций нейронов (это равносильно аппроксимации линейной функции более сложными функциями: сигмоидной или гиперболическим тангенсом).
Проведен аналогичный анализ и данных 2 и 3 кластеров. Поучительна картина рисунка 1, на котором приведена зависимость y = f(x2) для 2-го кластера. Наблюдается 4 выпадающие точки. Метод наименьших квадратов строит абсолютно неприемлемое уравнение, в то время как метод минимизации модулей остатков совсем «не обращает внимания» на выпадающие точки и ориентируется только на основную «массу» точек.

Рисунок 1. Иллюстрация влияния метода построения регрессионной зависимости по одним и тем же данным на результат
В процессе построения окончательных уравнений, описывающих данные кластеров, было удалено из: 1-го кластера 2 точки; 2-го кластера 4 точки; 3-го кластера 10 точек. На рис. 2, 3, 4 представлены оставшиеся точки кластеров и описывающие их уравнения.

Рисунок 2. Зависимость выручки от себестоимости для данных первого кластера
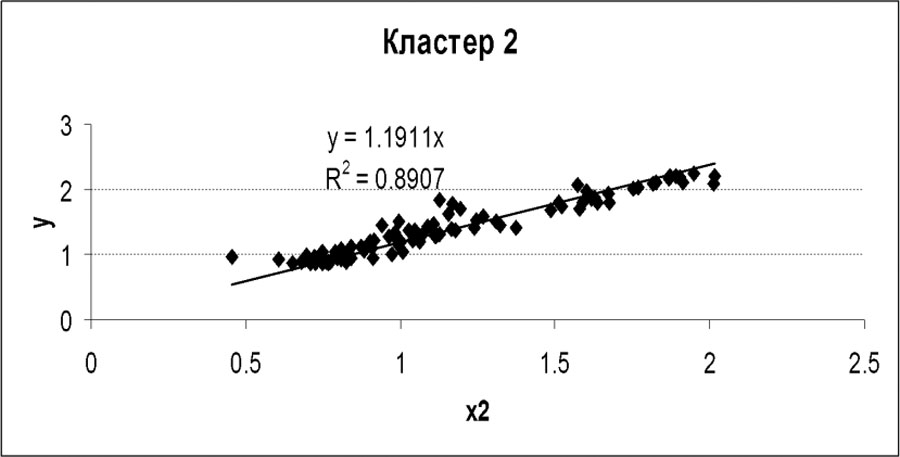
Рисунок 3. Зависимость выручки от себестоимостидля данных второго кластера
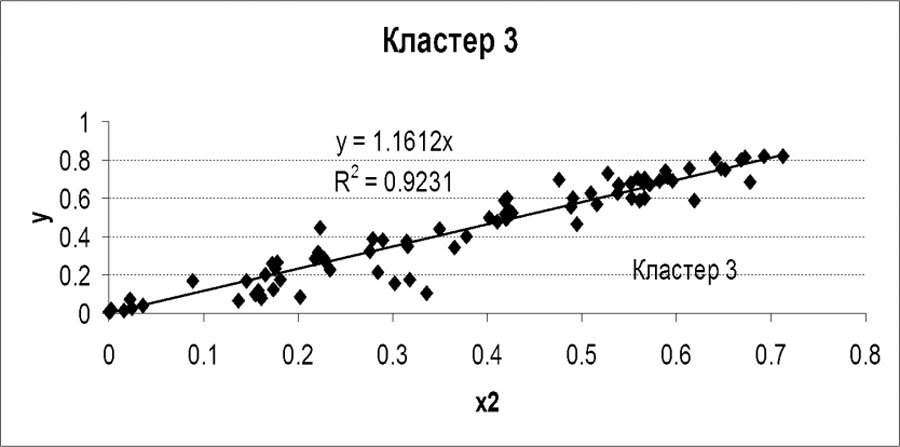
Рисунок 4. Зависимость выручки от себестоимости для данных третьего кластера
Замечаем, что данные всех кластеров описываются одинаковыми уравнениями y = f(x2) cнезначительно различающимися коэффициентами и очень высокими значениями коэффициентов детерминации, а это говорит о высоком качестве аппроксимации данных. При построении уравнений было задано условие y= f(0) = 0.
Близость коэффициентов уравнений кластеров подсказывает возможность описания данных всех кластеров одним уравнением. На рисунке 5 представлены соответствующие результаты. Коэффициент единого уравнения всех кластеров имеет среднее значение коэффициентов отдельных уравнений и очень близок к ним. Значение коэффициента детерминации R2= 0.9944 говорит о высоком качестве полученного единого уравнения.

Рисунок 5. Зависимость выручки от себестоимости для объединенных данных всех кластеров
Список литературы:
1.Букаев Г. И., Бублик Н. Д. и др. Модернизация системы налогового контроля на основе нейросетевых информационных технологий. —М.: Наука, 2001. —344 с.
2.Сахабетдинов М.А. Выявление аномальных наблюдений в регрессионном анализе. В трудах Всероссийской научно-практической конференции с международным участием «Информационные технологии в обеспечении нового качества высшего образования» (14—15 апреля 2010 г., Москва, НИТУ «МИСиС»)». Книга 3. —М.: Исследовательский центр проблем качества подготовки специалистов, 2010. с. 174—179.
3.Сахабетдинов М.А. Математическое моделирование экономических объектов с использованием идей теории подобия. В трудах III международной научно- практической конференции «Основные направления повышения эффективности экономики, управления и качества подготовки специалистов (МК‑90‑95)», Пенза, декабрь 2005, с. 135‑138.
дипломов