
Статья опубликована в рамках: XLIV Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 26 июля 2016 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
дипломов
ТЕСТИРОВАНИЕ МЕТОДА ПОСТРОЕНИЯ СЕМАНТИЧЕСКОЙ СЕТИ НАУЧНОГО ТЕКСТА

Введение. В настоящее время, так называемую, эпоху компьютеризации, бумажные документы постепенно теряют свою функциональность и актуальность. Они повсеместно вытесняются электронными документами, которые намного легче и быстрее создавать, редактировать, передавать практически любому адресату через Интернет. Вследствие этого их количество и объем значительно возросли, и теперь человеку все труднее самому определять и обрабатывать такие массивы информации. Одним из путей решения подобных задач необходимо найти такие способы представления знаний, которые помогут компьютеру понимать и анализировать смысл текста.
С недавних пор группой исследователей на кафедре успешно применяется способ представления знаний в виде семантической сети [1-2]. При построении семантической сети используется онтология предметной области [3]. Однако отсутствие полных онтологий предметных областей не позволяет выполнить полномасштабных вычислительных экспериментов, подтверждающих достоверность реализованных методов построения семантической сети. Построение онтологий предметных областей – это трудная, но необходимая задача, требующая понимания не только структуры онтологий, но и предполагающая наличие представлений в самой предметной области.
Краткое описание задачи. Для существующей программы построения семантической сети научного текста следует разработать и реализовать модуль, позволяющий проводить эксперименты. Во-первых, необходимо проверить правильность алгоритмов, в которых заложено обращение к онтологии предметной области. Во-вторых, следует определить зависимость выходных данных от входных. В-третьих, достаточно важно исследовать правильность выделения терминов и отношений текста, а также расчет их весовых коэффициентов. Программа эксперимента представлена в таблице 1.
Таблица 1 – Программа эксперимента
|
Наименование направления |
Разработка и развитие информационных технологий в области определении семантики текста |
|
Тема эксперимента |
Тестирование модуля построения семантической сети научного текста |
|
Объект исследования |
Модуль определения терминов и отношений текста и их весовых коэффициентов |
|
Предмет исследования |
Метод выделения терминов и отношений Способ расчета весовых коэффициентов вершин и дуг семантической сети |
|
Цель эксперимента |
Проверить методы построения семантической сети |
|
Гипотеза исследования |
Весовые коэффициенты вершин и дуг семантической сети адекватно отражают значимость терминов и отношений, находящихся в вершинах и дугах, для передачи смысла научного текста |
|
Задачи эксперимента |
1. Проверить полноту выделения терминов текста, принадлежащих рассматриваемой области знаний и находящихся в онтологии 2. Проверить полноту выделения отношений текста, принадлежащих рассматриваемой области знаний и находящихся в онтологии 3. Проверить правильность выделения тематики текста 4. Проверить правильность определения содержательно-смысловых блоков 4. Проверить правильность расчета весовых коэффициентов |
|
Методы исследования |
Моделирование, обобщение, формализация |
|
Этапы эксперимента |
1. Выбор предметной области 2. Подготовка тестовых научных текстов 3. Подготовка онтологии предметной области 4. Запуск программного модуля на тестовых наборах данных 5. Обобщение полученных результатов 6. Запуск программного модуля на множестве научных текстов, не входящих во множество тестовых наборов |
Проектирование программного модуля. Гипотеза исследования и задачи эксперимента позволяют представить будущий функционал модуля тестирования метода построения семантической сети. Диаграмма прецедентов (Use Case Diagram) схематически отображает отношения актеров и прецедентов (вариантов использования). Вариант использования является описанием последовательности действий, которые осуществляются системой при взаимодействии с актерами. Прецедент является частью функциональности моделируемой системы, используя которую пользователь получает необходимые результаты. Актером является любая внешняя, взаимодействующая с моделируемой системой сущность, которая использует различные ее сервисы для получения конкретных результатов. При этом актер обозначает множество логически связанных ролей, отыгрываемых пользователями в процессе использования проектируемой системы. Следует заметить, что актер может рассматриваться и как определенная роль относительно конкретного прецедента. На рисунке 1 представлена диаграмма прецедентов проектируемого модуля. Один актер – Исследователь, проводит тестирование метода построения семантических сетей путем взаимодействия с сервисами моделируемой системы. Исследователь может выбрать текст для анализа формата txt, онтологию, представленную в отдельном файле формата xml, программное приложение, которое строит семантическую сеть. Кроме этого исследователь может выбрать дополнительные онтологии, которые могут быть полезны для научных текстов смежных предметных областей. Просмотр результатов обработки текста – основная функция модуля тестирования, которая заключается в отображении списка терминов текста, списка отношений текста, их весовых коэффициентов, статистических данных, темы текста. Статистические данные – это количество терминов, количество и тип отношений, их процентное соотношение к общему числу терминов и отношений текста. Функция «Просмотр терминов, встречающихся в онтологии» расширяет функцию «Просмотр списка терминов» и выделяет термины, встречающиеся в онтологии.
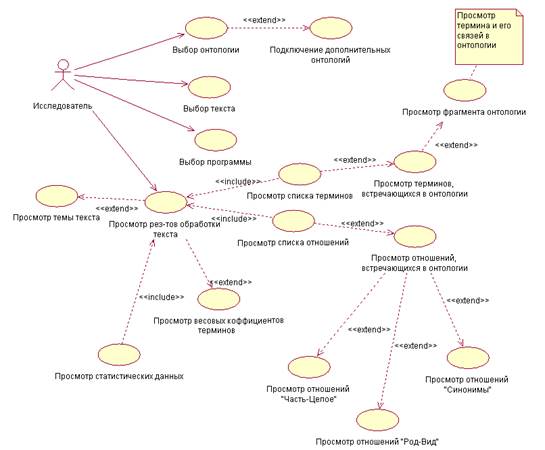
Рисунок 1 – Диаграмма прецедентов модуля
Аналогично работает и функция «Просмотр отношений, встречающихся в онтологии». Кроме этого удобным расширением является возможность отдельно просмотреть термины, находящиеся в отношении синонимии, «Род-Вид», «Часть-Целое».
Программный модуль. На рисунке 2 представлен интерфейс разработанного программного модуля.
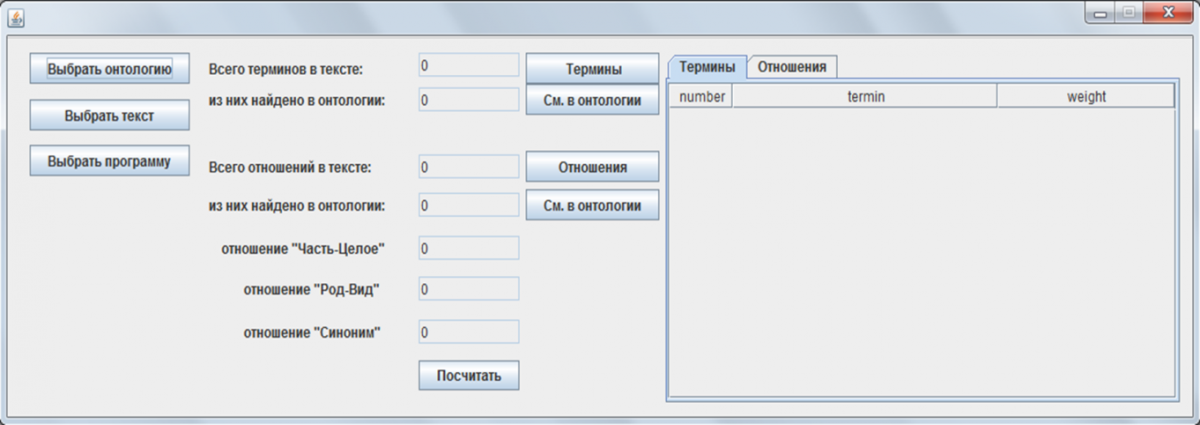
Рисунок 2 – Интерфейс программного модуля
На вход модуля подается онтология предметной области в xml-документе, файл с расширением .txt, в котором находится текст, и программа построения семантической сети научных текстов, для которой и был разработан данный модуль тестирования.
С помощью разработанного модуля были проведены эксперименты. Для этого была создана онтология предметной области «Управление персоналом» и подготовлены научные тексты.
Заключение. В результате проведения экспериментов было установлено, что в целом метод построения семантической сети, основанный на выделении терминов и отношений, выдает адекватные результаты, но имеются некоторые неточности, которые зависят от шаблонов именных словосочетаний и полноты морфологических словарей.
Список литературы:
1. Аюшеева Н.Н., Гомбожапова Т.Н. Разработка методов построения семантической сети текста: моногр. – Улан-Удэ: Изд-во ВСГУТУ, 2016. – 124 с.
2. Аюшеева Н.Н., Кушеева Т.Н. Способ вычисления весовых коэффициентов вершин семантической сети научного текста // Фундаментальные исследования. – 2012. – №6 (Ч. 3). – С. 626-631.
3. Найханова Л.В. Технология создания методов автоматического построения онтологий с применением генетического и автоматного программирования. – Улан-Удэ: Изд-во БНЦ СО РАН, 2008. – 243 с.
дипломов