
Статья опубликована в рамках: XIII Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 31 октября 2013 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

РАСПОЗНАВАНИЕ РЕЧИ В СТАЦИОНАРНЫХ СИСТЕМАХ
Дриленко Максим Владимирович
студент, ИИТиБ, КубГТУ, Краснодар
E-mail: maxis@russia.ru
Луцко Николай Андреевич
научный руководитель, старший преподаватель, кафедра ОМ, КубГТУ, Краснодар
В настоящее время все большую популярность получают так называемые интерактивные системы обработки информации, которые на основе определенных входных данных и с использованием специализированных алгоритмов, позволяют пользователю даже не иметь представления о функционировании устройства, получить конкретный ответ на поставленный вопрос. Такие системы все чаще используются не только в узкоспециализированных областях, но и появляются на потребительском рынке. Достаточно вспомнить «умные стиральные машины» или автомобили, которые имеют функцию автоматической парковки. Множество международных компаний ведут активные исследования в области разработки систем голосового управления, которые позволяют использовать устройства без непосредственного физического контакта с ними, к таким компания относятся интернет-гиганты, а именно российский Яндекс и американский Google. Данные компании постоянно совершенствуют свои технологии преобразования голосового запроса в поисковой запрос, что выводит продукты этих компаний на новый уровень. Однако, стоит отметить что сами технологии позволяют преобразовать в текст только наиболее часто используемые слова, такие, которые люди используют в повседневной жизни, и делает невозможным обработку специфических фраз, формул и пр. Это делает технологию распознавания ограниченной по области действия. Проведенное исследование указывает на возможности обработки запросов в стационарных системах.
Большинство средств обработки сигналов работают в стационарных системах, т. е. подразумевают стационарный сигнал. Следовательно, средства, которые применяются для обработки сигналов не подходят для обработки речи. Использование их напрямую нарушает лежащие в их основе предположения. И даже если использовать их, результат не будет иметь практического значения. Например, вычисление общей энергии, которое лежит в основе в области обработки сигналов:
![]()
Допустим, что можно использовать эту формулу для вычисления энергии речи. Однако, полученное значение ничего не даст. Причина лежит в природе речи она имеет меняющуюся во времени энергию и амплитуду, поэтому необходим инструмент, который предоставил бы информацию об изменениях энергии во времени.
Было предложено решение для обработки речи [5, с. 128], которое заключалось в использовании уже известных методов из области обработки сигналов с их небольшой модификацией. Т. е. используемые средства обработки так же предполагали стационарный сигнал. Стационарным речевой сигнал получается, когда рассматривается небольшими блоками по 10-30мс. Следовательно, для обработки речи средствами обработки сигналов, она рассматривается в блоках по 10—30 мс (дальше такой участок будем называть речевым сигналом). Такая обработка называется Краткосрочной Обработкой (Short Term Processing (STP)).
Short Term Energy
Назовем энергией некую величину, которая характеризирует сам сигнал. Энергия речи изменяется во времени из-за своей природы и потому, для любой ее автоматической обработки важно знать, как энергия изменяется во времени. По происхождению, речевой сигнал состоит из речевых и неречевых участков. Энергия участка с речью по своей величине больше энергии неречевого участка, в то время как энергия тишины близка к нулю. Таким образом, характеристика STP может быть использована при классификации голосовых и участков, не содержащих голоса, что является признаком присутствия речи или тишины.
Формулу для нахождения краткосрочной энергии можно вывести из формулы полной энергии определенной в области обработки сигналов. Полная энергия сигнала вычисляется по формуле:

Для вычисления краткосрочной энергии мы рассматриваем участок речи длительностью 10-30мс. Допустим что количество энергии в определенном диапазоне будем перечислять от n=0 до n=N-1, где N — длительность. За границами диапазона энергия будет равна нулю. Таким образом получаем:
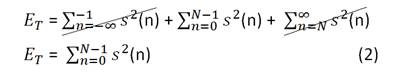
Таким образом, формула дает полную энергию в блоке речи.
![]()
где w(n) — оконная функция — в литературе по обработке сигналов упоминается несколько таких функций. Чаще всего используется прямоугольное окно:
![]()
окно Ханна:
![]()
или окно Хемминга:
![]()
Для всех характеристик, вычисляемых во временной области будем использовать прямоугольное окно из-за его простоты.
Теперь можно полностью записать формулу расчета краткосрочной энергии речи в блоке:
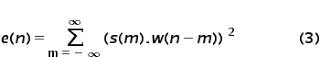
где: n — сдвиг. Поскольку изменения энергии в случае с речью незначительны, то считать краткосрочную энергию с малым сдвигом не имеет смысла.
Таким образом, становится очевидной необходимость использования более сложной математики при обработке комплексных запросов. Алгоритм обработки стационарных сигналов может повысить качество распознавания речи, которая во многом зависит от качества речи пользователя, улучшение технологий распознавания в области обработки специализированных слов и формул повысит и качественную сторону работы с персональным компьютером и любым другим устройством, использующим подобный алгоритм. Системы, организованные по принципу клиент-серверных технологий могут значительно снизить нагрузку на микропроцессор устройства, обрабатывающего речь, но безопасность таких запросов может вызывать значительные опасения, например, компания Google официально сообщила, что использует голосовые запросы пользователей, которые вызвали затруднения у поисковой системы в качестве материала для обучения системы распознавания речи, это означает, то все запросы пользователей к поисковой системе посредством голосовых команд, хранятся на серверах компании.
Подытожив все вышесказанное можно предположить, что развитие алгоритмов распознавания речи, которые будут иметь возможность качественного распознавания речи без потерь мощности и времени на устройстве пользователя, без обработки запроса на стороне сервера (в облаке) будут иметь большой успех в различных областях, и, несомненно, получит одобрение множества пользователей. Использование математического аппарата, представленного в данной статье позволяет производить распознавание сигнала в стационарных системах и уже может являться основой систем распознавания речи.
Список литературы:
1.Насыпный В.В., Желтов С.Ю., Ососков М.В. Распознавание и понимание смысла речи в шумах на основе стохастики. // GraphiCon-2002, — 23 с.
2.Bretzner L., Mersereau R.M. Разработка систем распознавания речи. // Proc. of the 5, с. 19th Int. Conf. on Automatic Recognition, 2002 — 6 с.
дипломов