
Статья опубликована в рамках: X Международной научно-практической конференции «Наука вчера, сегодня, завтра» (Россия, г. Новосибирск, 12 марта 2014 г.)
Наука: Технические науки
Скачать книгу(-и): Сборник статей конференции
- Условия публикаций
- Все статьи конференции
дипломов

Статья опубликована в рамках:
Выходные данные сборника:
СОВРЕМЕННЫЕ ПЛАТФОРМЫ ИНТЕЛЛЕКТУАЛЬНОЙ АНАЛИТИЧЕСКОЙ ОБРАБОТКИ ИНФОРМАЦИИ: ГРАФОВЫЕ БАЗЫ ДАННЫХ
Климанская Елена Владимировна
аспирант РГУПС, РФ, г. Ростов-на-Дону
E -mail: inf-rgups@yandex.ru
Работа выполнена при поддержке РФФИ, проекты 13-08-12151-офи_м; 13-07-13159-офи_м_РЖД
По оценкам информационно-аналитической компании IDC (International Data Corporation) объемы «цифровой вселенной» (Digital Universe) [1] к 2020 году могут достигнуть 40 зеттабайтов, то есть 40 триллионов гигабайтов, из которых до 80 % будет составлять так называемая плохо-, слабоструктурированная информация, циркулирующая в виде интервальных медиа-потоков, информации социальных медиа-сетей, сетевых мобильных устройств и так далее. Графическая иллюстрация, по данным IDC, приведенная на рис. 1, показывает соотношение структурированной и слабоструктурированной информации в современной Digital Universe.
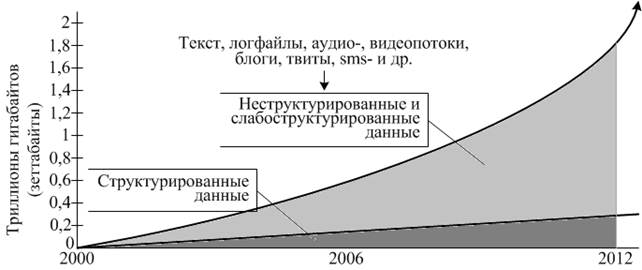
Рисунок 1. Соотношение структурированной и слабоструктурированной информации в Digital Universe
Превалирование слабоструктурированных данных над структурированными, как и мультиструктурной модели данных над реляционной моделью, отмечается и в аналитических материалах исследований IT-рынка компанией Gognizant, см. рис. 2.
Основными поставщиками, обработчиками и хранителями данных в современной Digital Universe являются распределенные сетевые системы и устройства различного назначения. Среди корпоративных сетевых информационно-управляющих систем сверхбольшого масштаба можно выделить комплекс автоматизированных систем управления железнодорожным транспортом, построенный на основе сети передачи данных ОАО «РЖД» и насчитывающий тысячи подсистем и сотни тысяч сетевых рабочих мест [2].

Рисунок 2. Соотношение мультиструктурных моделей данных и реляционных моделей
Хранилища данных, используемые в подавляющем большинстве сетевых информационных систем, в том числе и в автоматизированных системах управления на железнодорожном транспорте, основываются на реляционной модели данных. Однако, информационно-управляющие системы на железнодорожном транспорте подвергаются в настоящее время интенсивной «интеллектуализации», касающейся различных аспектов поддержки принятия решений в сложных, протекающих в реальном времени транспортных процессах. Таким образом, интеллектуализация транспортных процессов потребует, как и любая интеллектуальная технология, учета слабоформализуемой, возможно не полностью определенной, нечеткой, темпорально-валидной, пространственно-распределенной информации и, как следствия, получения структурированных, слабоструктурированных и неструктурированных данных.
Принятие решений в условиях получения этих видов данных отнюдь не означает их смысловую разнородность, а, наоборот, подчеркивает факт, что данные семантически одинаковы, дополняют друг друга и направлены на повышение эффективности принимаемого решения. В качестве примера использования неструктурированных, слабоструктурированных и структурированных данных в принятии решения о ремонте вагона в железнодорожном депо можно привести соответственно: приказ и наряд на назначение ремонтной бригады; методику и руководящие указания и инструкции по ремонту; каталог запчастей для исполнения ремонта вагона. Увеличение числа задач аналитической и интеллектуальной обработки больших объемов данных во всех сферах деятельности человека приводит к потребности создания универсальных архитектур анализа мультиструктурированной информации. Такую архитектуру, учитывающую свойства распределенности и масштабируемости, можно представить на рис. 3.
Эта архитектура кроме интегрированного доступа к неструктурированной, слабоструктурированной информации обеспечивает также набор инструментов для нормализации, индексирования, представления, визуализации, анализа и построения аналитических отчетов из единого хранилища данных. Реализуется представленная архитектура в нескольких проектах и программных комплексах. Одним из таких проектов является SMILA (SeMantic Information Logistic Architecture, Семантическая информационная логистическая архитектура), которая относится к фреймворку Eclipse [3].
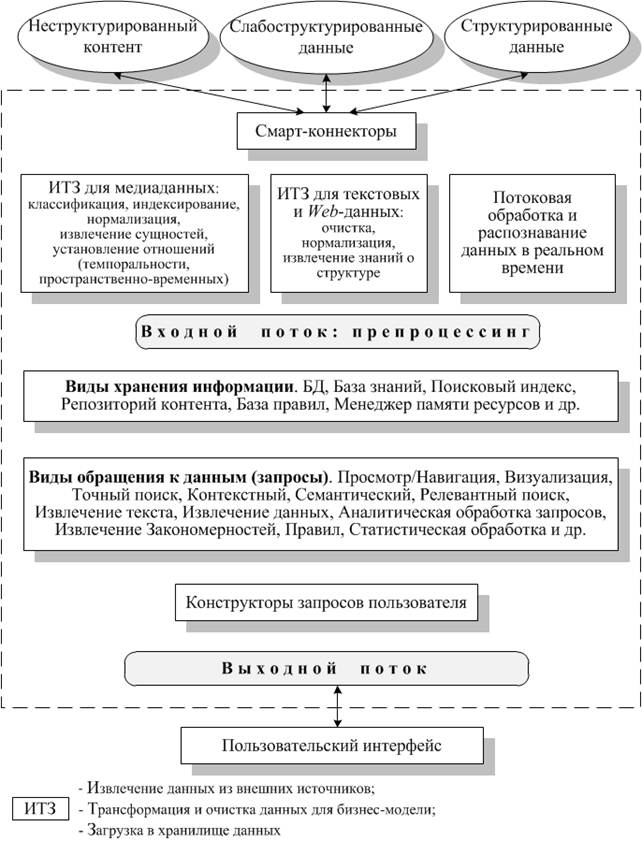
Рисунок 3. Универсальная архитектура интеллектуального анализа мультиструктурированной информации
Областью применения SMILA является создание высокомасштабируемых серверных систем обработки, поиска, лингвистического анализа и извлечения информации похожей семантики. Основными компонентами фреймворка являются: 1) JobManager, предназначенный для асинхронной масштабируемой обработки информационных задач; 2) Crawlers, масштабируемые компоненты извлечения данных заданного формата из разнородных источников; 3) Pipelines, обработчики запросов в виде pipelets-компонентов; 4) Storage, интегрированные хранилища «больших данных».
В архитектуре SMILA, во-первых, данные, импортируемые в хранилище, подвергаются извлечению из разнородных сетевых источников посредством протокола HTTP и набора функций REST API многопоточным (с помощью JobManager) способа. Для каждого документа, кроме его самого строится запись метаданных документа посредством Crawlers-компонентов и поисковые индексы. Эти действия являются подготовительными для извлечения онтологий и помещения их в хранилище онтологий. Во-вторых, архитектура SMILA позволяет отвечать на поисковые запросы пользователей компонентами pipelets [4], обрабатывающими коммуникационные паттерны пользователей, описываемые на языке формального описания бизнес-процессов BPEL (Business Process Execution Language, язык выполнения бизнес-процессов) [5].
Другим примером теперь уже коммерческой платформы для аналитической обработки больших массивов плохо структурированных данных являются решения компании Teradata. Наряду с хорошо известными продуктами Teradata Database, Teradata Columnar, Teradata Temporal, реализующими реляционную, поколоночную и гибридную модели хранения записей в базе данных (БД) с массово-параллельной архитектурой MPP (Massive Parallel Processing) в последнее время предлагается Teradata Aster Discovery Platform (после поглощения компании Aster Data в 2011 году). Эта платформа [6] включает:
1. Teradata Aster SQL-GR, платформу аналитической обработки графовой информации на основе BSP (Bulk Synchronous Parallel, параллельной синхронной модели вычислений для больших объемов данных);
2. Teradata SNAP Framework (Seamless Network Analytic Processing, фреймворк беспроводной сетевой аналитической обработки графовых, текстовых, статистических данных, временных рядов, SQL-запросов методами Mapreduce);
3. Teradata Aster File Store — файловую систему, предназначенную для хранения сверхбольших объемов данных в различных форматах, в том числе HDFS (Hadoop Distributed File System, распределенной файловой системы Haddop).
Объяснив возрастающий интерес к хранению и обработке больших объемов неструктурированных и слабоструктурированных данных, обратимся теперь к одному из наиболее перспективных подходов — графовым БД. Практическое объяснение принципов организации графовых данных в БД можно найти в работе [7].
Рассмотрим несколько современных реализаций графовых моделей данных в виде программных продуктов. Любая из описанных ниже БД предназначена для удобного хранения и доступа к данным, представленным в виде графов большой размерности (миллионы и более узлов и связей между ними). Однако, по своим функциональным возможностям графовые БД можно классифицировать на следующие виды:
1. БД с локальным хранением и обработкой графов;
2. БД с распределенным хранением и обработкой данных;
3. БД в формате «ключ-значение»;
4. документо-ориентированные БД;
5. надстройки над SQL-ориентированными БД;
6. графовые БД с моделью MapReduce.
Классическим представителем первого вида является полностью транзакционная (ACID, Atomicity Consistency Isolation Durability, Атомарность Согласованность Изолированность Надежность) графовая БД Neo4j [8]. Эта БД на сегодняшний день является безусловным лидером по количеству использований (инсталляций). К этому же виду относится HyperGraphDB — фреймворк, ориентированный на хранение данных в виде гиперграфов, а также AllegroGraph, являющаяся частично-транзакционной графовой БД. Первые две из перечисленных выше являются программами с открытым исходным кодом, а третья имеет бесплатную версию с ограничениями на хранение не более 5 миллионов узлов графа. К такому виду относится также БД Sparksee, поддерживающая целый спектр операционных систем, включая мобильные iOS и Android.
К базам данных второго вида относятся: 1) исследовательский проект подразделения Extreme Computing Group компании Microsoft Research, называемый Horton (Querying Large Distributed Graphs, Обработка больших распределенных графов); 2) InfiniteGraph. Особенностями хранения графов в таких БД является разделение их на подграфы по распределенным сетевым вычислительным комплексам, а затем — организация параллельных вычислений по различным моделям и коммуникационным протоколам.
Третий вид графовых БД включает в себя еще один исследовательский проект компании Microsoft Research с названием Trinity. Это распределенная система обработки графовой информации в глобально адресуемом облаке оперативной памяти, являющаяся хранилищем в формате «ключ-значение» на кластере вычислительных узлов. В формате «ключ-значение», но с возможностями хранения графов как в оперативной, так и в дисковой памяти узлов облака функционирует графовая БД CloudGraph. Она также является полностью транзакционной ACID БД и имеет свой графический язык запросов GQL (Graph Query Language). База данных RedisGraph использует быстрое, размещаемое в оперативной памяти Redis-кэш хранилище «ключ-значение» и минималистичный программный интерфейс взаимодействия с ним. По минималистичности функционала, прежде всего связанного с повышением производительности, не уступает указанной БД и графовая БД VertexDB, использующая для запросов HTTP-протокол и JSON для формата хранения данных графов.
Для четвертого вида баз данных характерно хранение документов, аналогично как это осуществляется в документо-ориентированных БД, однако, связи между документами хранятся и обрабатываются посредством графовых моделей и методов. Наиболее известным представителем этого вида БД является OrientDB. Эта БД поддерживает ACID транзакции, а также интерфейс Blueprints для универсального доступа к графовым данным и БД, некоторые из которых ранее перечислены.
К графовым БД пятого вида, функционирующим на базе SQL-поддержки относится Filament. Более точно, эта БД является библиотекой, предназначенной для хранения и обработки графовых данных, которая выполнена в виде надстройки над базой данных PostgreSQL и интерфейса доступа JDBC. К такому же виду графовых БД относится G-Store, называемая самими разработчиками «lightweight disk-based manager for graph data», то есть дисковым менеджером (надстройкой над PostgreSQL) для графовых данных.
И, наконец, к шестому виду графовых БД, использующих возможности модели распределенных вычислений для обработки больших объемов данных за один проход MapReduce относятся проекты: Pregel, Apache Giraph, GraphLab. Проект Pregel компании Google использует также идеи BSP обработки данных. Реализация графовых алгоритмов осуществляется в рамках последовательностей итераций, называемых «супершагами» BSP, в результате которых вычисляются в параллельном режиме некоторые, задаваемые пользователями функции вершин графа. Супершаг является неделимой единицей параллельных вычислений. В процессе исполнения вычислений, по мере готовности результатов формируются служебные сообщения, которыми обмениваются между собой функции вершин графов для обозначения смены своих состояний (активное, когда вычисления продолжаются и неактивное, когда вычисления выполнены) по автоматному принципу vertex state machine (автомат состояний вершины). Проект Apache Giraph, является, по сути, аналогом проекта Pregel, попадающим под лицензию свободного программного обеспечения Apache License (Apache Software Foundation), который использует Hadoop, то есть модель MapReduce с использованием распределенной файловой системы HDFS (Hadoop Distributed File System), а в качестве менеджера синхронизации состояний вершин применяется сервер синхронизации Apache Zookeeper. GraphLab представляет собой набор программных инструментов для реализации высокопроизводительной параллельной распределенной обработки графовых данных и программирования собственных алгоритмов графовых вычислений с хранением результатов в файловой системе HDFS. Эта платформа имеет в своем составе также подсистему машинного обучения, предназначенную для извлечения знаний из графовых данных.
В заключении можно отметить, что несмотря на превалирование систем управления и серверов БД, построенных на реляционных принципах, графовые БД начинают постепенно занимать свое место в платформах для аналитической интеллектуальной обработки информации. Большинство из вышеперечисленных проектов являются некоммерческими, имеющими лицензии свободного программного обеспечения, используются сейчас скорее в исследовательских, а не научных целях. Однако, не исключено, что при успешном продвижении и принятии идей графовой обработки слабоструктурированных данных, какие-либо проекты получат достаточно широкую поддержку и развитие в сфере информационного менеджмента, анализа данных, принятия решений и интеллектуальных технологий.
Список литературы:
1.Климанская Е.В., Дергачев В.В., Бутакова М.А. Архитектура современных информационных систем на транспорте, проблемы их интеграции, математического и программного обеспечения: Материалы XIII Международной научно-практической конференции «Компьютерные технологии в науке, производстве, социальных и экономических процессах», г. Новочеркасск, 12 декабря 2012 г. // Юж.-Рос. гос. техн. ун-т (НПИ). Новочеркасск: ЮРГТУ, 2013. — С. 12—21.
2.IDC 2013 Digital Universe Study. [Электронный ресурс] — Режим доступа. — URL: http://www.emc.com/leadership/digital-universe/iview/index.htm (дата обращения 07.03.2014).
3.SMILA. [Электронный ресурс] — Режим доступа. — URL: http://www.eclipse.org/smila/ (дата обращения 07.03.2014).
4.Jahn J., Henkel J. Pipelets: self-organizing software pipelines for many-core architectures // DATE’13 Proceedings of the Conference on Design, Automation and Test in Europe, 2013. — P.P. 1516—1521.
5.Online community for the Web Services Business Process Execution Language OASIS Standard. [Электронный ресурс] — Режим доступа. — URL:http://bpel.org (дата обращения 07.03.2014).
6.Simmen D. Reveal Relationships // Teradata Magazine Online, № 1, 2014. — [Электронный ресурс] — Режим доступа. — URL:http://www.teradatamagazine.com/v14n01/Tech2Tech/Reveal-Relationships (дата обращения 07.03.2014).
7.Robinson I., Webber J., Eifrem E. Graph Databases. O’Reilly Media, Inc. 2013. — 210 p.
8.Neo4j. [Электронный ресурс] — Режим доступа. — URL: http://www.neo4j.org (дата обращения 07.03.2014).
дипломов
Оставить комментарий